This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Machine learning algorithms are classified into three types: supervisedlearning, The post K-Means Clustering Algorithm with R: A Beginner’s Guide. appeared first on Analytics Vidhya.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Model selection and training: Teaching machines to learn With your data ready, it’s time to select an appropriate ML algorithm. Popular choices include: Supervisedlearning algorithms like linear regression or decision trees for problems with labeled data.
For instance, for culture, we have a set of embeddings for sports, TV programs, music, books, and so on. The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning. We can then use pgvector to find articles that are clustered together.
This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data. Types of Machine Learning for GIS 1. Supervisedlearning– In supervisedlearning, the input data and associated output labels are paired, letting the system be trained on labelled data.
Learning Resources To master Python for Data Science, accessing high-quality learning resources catering to beginners and professionals is essential. From structured online courses to insightful books and tutorials and engaging YouTube channels and podcasts, a wealth of content guides you on your journey.
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Clustering. Classification. Regression.
Building on In-House Hardware Conformer-2 was trained on our own GPU compute cluster of 80GB-A100s. To do this, we deployed a fault-tolerant and highly scalable cluster management and job scheduling Slurm scheduler, capable of managing resources in the cluster, recovering from failures, and adding or removing specific nodes.
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” Let’s go back to our history book analogy. That’s how RAG works.
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” Let’s go back to our history book analogy. That’s how RAG works.
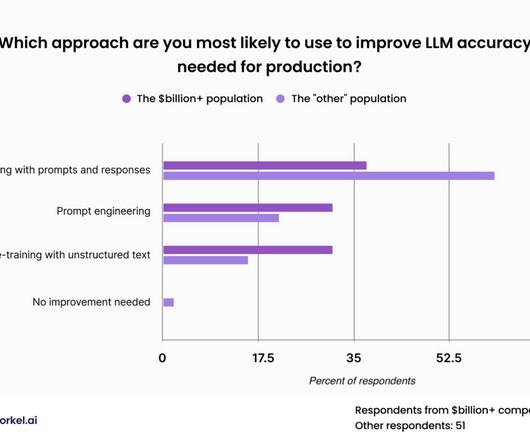
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
How to Learn Python for Data Science in 5 Steps In order to learn Python for Data Science, following are the 5 basic steps that you need to follow: Learn the Fundamentals of Python: Learn the basic principles of the Python programming language. It includes regression, classification, clustering, decision trees, and more.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Book a demo today. But it’s not that straightforward. Data scientists can clean this up ahead of pre-training in a number of ways.
For example, You can learn Python on Pickl.AI Books : “Automate the Boring Stuff with Python” is excellent for those who prefer self-paced learning. Deep Learning is a subset of ML. Unsupervised learning focuses on uncovering hidden patterns in unlabeled data.
For those who are non-tech-savvy , machine learning, a cornerstone of artificial intelligence, trains computers to interpret data and make decisions. It’s divided primarily into three types: supervised, unsupervised, and reinforcement learning.
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content