This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
The post Upcoming DataHour Sessions: Book your Calendars! To provide our community with a better understanding of how different elements of the subject are used in different domains, Analytics Vidhya has launched our DataHour sessions. These sessions will enhance your domain knowledge and help you learn new […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article we will be discussing Binary Image Classification. The post Image Classification with TensorFlow : Developing the DataPipeline (Part 1) appeared first on Analytics Vidhya.
This can be useful for data scientists who need to streamline their data science pipeline or automate repetitive tasks. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
Home Table of Contents Adversarial Learning with Keras and TensorFlow (Part 2): Implementing the Neural Structured Learning (NSL) Framework and Building a DataPipeline Adversarial Learning with NSL CIFAR-10 Dataset Configuring Your Development Environment Need Help Configuring Your Development Environment? We open our config.py
Aspiring and experienced Data Engineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best Data Engineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is Data Engineering?
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
If you’ve enjoyed the list of courses at Gen AI 360, wait for this… Today, I am super excited to finally announce that we at towards_AI have released our first book: Building LLMs for Production. This 470-page book is all about LLMs and how to work with them. Join thousands of data leaders on the AI newsletter.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Its diverse content includes academic papers, web data, books, and code. EleutherAI created the Pile to democratise AI research with high-quality, accessible data. Diversity of Sources : The Pile integrates 22 distinct datasets, including scientific articles, web content, books, and programming code.
ODSC West is now a part of our history books, and we couldn’t be happier with how everything turned out. We had our first-ever Halloween party, more book signings, exciting keynotes, and plenty of sessions to fit everyone’s needs.
It offers a wealth of books, on-demand courses, live events, short-form posts, interactive labs, expert playlists, and more—formed from the proprietary content of thousands of independent authors, industry experts, and several of the largest education publishers in the world.
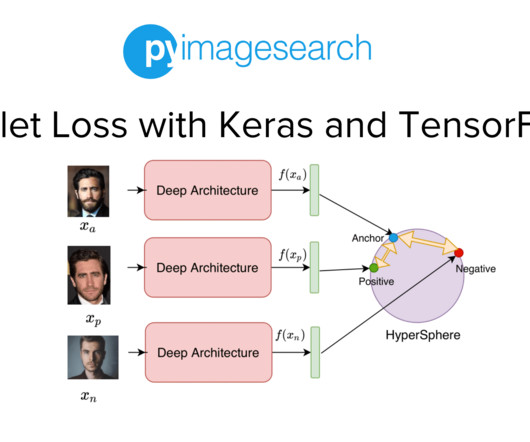
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Jump Right To The Downloads Section Training and Making Predictions with Siamese Networks and Triplet Loss In the second part of this series, we developed the modules required to build the datapipeline for our face recognition application. Figure 1: Overview of our Face Recognition Pipeline (source: image by the author).
Through simple conversations, business teams can use the chat agent to extract valuable insights from both structured and unstructured data sources without writing code or managing complex datapipelines. You can find him reading 4 books at a time when not helping or building solutions for customers.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders. Each API has its own set of requirements.
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down data silos and power their streaming datapipelines with trusted data. Book your meeting with us at Confluent’s Current 2023. See you in San Jose!
In the previous tutorial of this series, we built the dataset and datapipeline for our Siamese Network based Face Recognition application. Specifically, we looked at an overview of triplet loss and discussed what kind of data samples are required to train our model with the triplet loss. Download the code!
The groundwork of training data in an AI model is comparable to piloting an airplane. The entire generative AI pipeline hinges on the datapipelines that empower it, making it imperative to take the correct precautions. If the takeoff angle is a single degree off, you might land on an entirely new continent than expected.
He is the author of the upcoming book “What’s Your Problem?” Aaron Kesler is the Senior Product Manager for AI products and services at SnapLogic, Aaron applies over ten years of product management expertise to pioneer AI/ML product development and evangelize services across the organization.
Outside of work, he enjoys playing lawn tennis and reading books. Jeff Newburn is a Senior Software Engineering Manager leading the Data Engineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including data warehouses, visualizations, analytics, and machine learning.
DataPipeline Capabilities This team’s scope is massive because the datapipelines are huge and there are many different capabilities embedded in them. The team focuses on cleansing and transforming pieces of the data value stream, while seeking ways to further commoditize and standardize data.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. More Speakers and Sessions Announced for the 2024 Data Engineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 Data Engineering Summit.
You have a specific book in mind, but you have no idea where to find it. You enter the title of the book into the computer and the library’s digital inventory system tells you the exact section and aisle where the book is located.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. Booking – This demonstrates an example of routing the caller to a live agent queue. Choose an option for allowing unredacted logs for the Lambda function in the datapipeline. in the middle of a conversation.
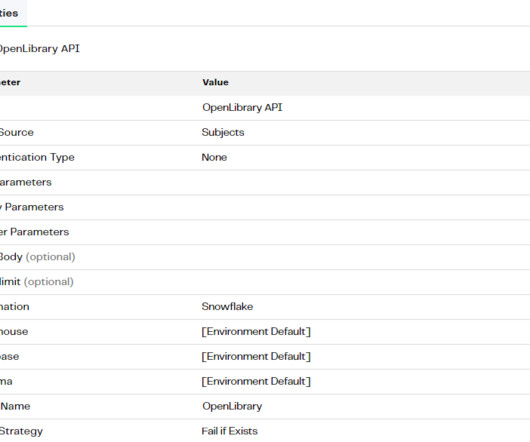
If you’d like a more personalized look into the potential of Snowflake for your business, definitely book one of our free Snowflake migration assessment sessions. These casual, informative sessions offer straightforward answers and honest advice for moving your data to Snowflake.
Market participants who are receiving either live or historical data feeds need to ingest this data and perform one or more steps, such as parse the message out of a binary protocol, rebuild the limit order book (LOB), or combine multiple feeds into a single normalized format.
I consciously chose to pivot away from general software development and specialize in Data Engineering. I’ve moved from building user interfaces and backend systems to designing data models, creating datapipelines, and gaining valuable insights from complex datasets.
Going Beyond with Keras Core The Power of Keras Core: Expanding Your Deep Learning Horizons Show Me Some Code JAX Harnessing model.fit() Imports and Setup DataPipeline Build a Custom Model Build the Image Classification Model Train the Model Evaluation Summary References Citation Information What Is Keras Core? Enter Keras Core!
Moreover, enterprises should consider lakehouse solutions that incorporate generative AI to help data engineers and non-technical users easily discover, augment and enrich data with natural language. Data lakehouses improve the efficiency of deploying AI and the generation of datapipelines.
Data governance for LLMs The best breakdown of LLM architecture I’ve seen comes from this article by a16z (image below). As new AI regulations impose guidelines around the use of AI, it is critical to not just manage and govern AI models but, equally importantly, to govern the data put into the AI.
Solution overview SageMaker algorithms have fixed input and output data formats. But customers often require specific formats that are compatible with their datapipelines. Option A In this option, we use the inference pipeline feature of SageMaker hosting. Dhawal Patel is a Principal Machine Learning Architect at AWS.
American Family Insurance: Governance by Design – Not as an Afterthought Who: Anil Kumar Kunden , Information Standards, Governance and Quality Specialist at AmFam Group When: Wednesday, June 7, at 2:45 PM Why attend: Learn how to automate and accelerate datapipeline creation and maintenance with data governance, AKA metadata normalization.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By thinking about the ML process in advance: preparing, managing, and versioning data, reusing components, etc.,
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a datapipeline. He is the author of the upcoming book “What’s Your Problem?” The humble beginnings with Iris In 2017, SnapLogic unveiled Iris, an industry-first AI-powered integration assistant.
Specifically, we will develop our datapipeline, implement the loss functions discussed in Part 1 and write our own code to train the CycleGAN model end-to-end using Keras and TensorFlow. Finally, we combine and consolidate our entire training data (i.e., Let us open the train.py file and get started.
From now on, we will launch a retraining every 3 months and, as soon as possible, will use up to 1 year of data to account for the environmental condition seasonality. When deploying this system on other assets, we will be able to reuse this automated process and use the initial training to validate our sensor datapipeline.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By thinking about the ML process in advance: preparing, managing, and versioning data, reusing components, etc.,
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of datapipelines.
Step 1 : Examine the Raw XML data (below is the sample XML data used for loading). The data contains a three-level nested structure: catalog → book → notes. Each catalog has multiple books; each book contains notes by publisher and author. Ensure to complete the steps listed under setup.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
To read more about LLMOps and MLOps, checkout the O’Reilly book “Implementing MLOps in the Enterprise” , authored by Iguazio ’s CTO and co-founder Yaron Haviv and by Noah Gift. Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. What is LLMOps?
We will understand the dataset and the datapipeline for our application and discuss the salient features of the NSL framework in detail. config.py ) The datapipeline (i.e., Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL! model.py ) Additionally, the robust.py
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content