30 Best Data Science Books to Read in 2023
Analytics Vidhya
FEBRUARY 28, 2023
To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
 Books Data Preparation Deep Learning
Books Data Preparation Deep Learning 
Analytics Vidhya
FEBRUARY 28, 2023
To achieve maximum efficiency, every company strives to use various data at every stage of its operations.

PyImageSearch
DECEMBER 23, 2024
We will start by setting up libraries and data preparation. Setup and Data Preparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vector. Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

PyImageSearch
OCTOBER 21, 2024
We will start by setting up libraries and data preparation. Setup and Data Preparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., detection of potential failures or issues). temperature, pressure, vibration, etc.) Download the code!
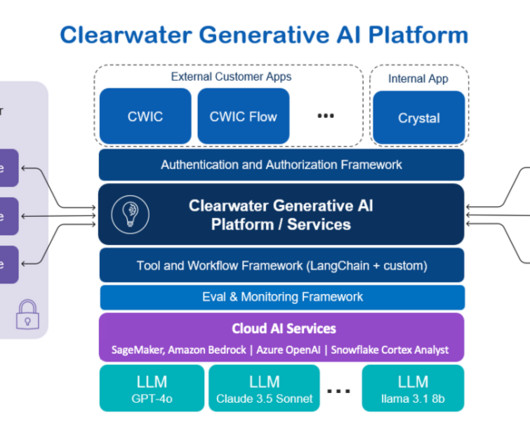
DECEMBER 13, 2024
This assistant framework is built upon three pillars: Knowledge awareness Using RAG, CWIC compiles and delivers comprehensive knowledge that is crucial for customers from intricate calculations of book value to period-end reconciliation processes. Pre-trained model teardown Remove the pre-trained model to free up resources.

AWS Machine Learning Blog
AUGUST 14, 2023
SageMaker JumpStart SageMaker JumpStart serves as a model hub encapsulating a broad array of deep learning models for text, vision, audio, and embedding use cases. Often, to get an NLP application working for production use cases, we end up having to think about data preparation and cleaning.

PyImageSearch
JANUARY 27, 2025
We will start by setting up libraries and data preparation. Setup and Data Preparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vectors. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

PyImageSearch
SEPTEMBER 16, 2024
We will start by setting up libraries and data preparation. Setup and Data Preparation To start, we will first download the Credit Card Fraud Detection dataset, which contains details (e.g., Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated?

Expert insights. Personalized for you.
















Let's personalize your content