This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You marked your calendars, you booked your hotel, and you even purchased the airfare. Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. To help you plan your agenda for this year’s re:Invent, here are some highlights of the generative AI and ML track.
ArticleVideo Book This article was published as a part of the Data Science Blogathon AGENDA: Introduction Machine Learning pipeline Problems with data Why do we. The post 4 Ways to Handle Insufficient Data In Machine Learning! appeared first on Analytics Vidhya.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Drawing from their extensive experience in the field, the authors share their strategies, methodologies, tools and best practices for designing and building a continuous, automated and scalable ML pipeline that delivers business value. The book contains a full chapter dedicated to generative AI.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. About the Authors Mair Hasco is an AI/ML Specialist for Amazon SageMaker Studio. Get started on SageMaker Studio here.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data scientist experience In this section, we cover how data scientists can connect to Snowflake as a data source in Data Wrangler and preparedata for ML.
Generative AI , AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. About SageMaker JumpStart Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. About the Authors Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS).
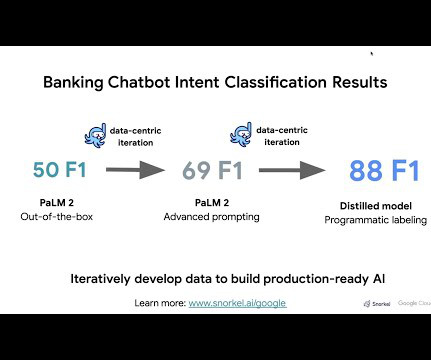
Enhanced user experience in Snorkel Flow Studio We’ve made significant improvements to Snorkel Flow Studio, making it easier for you to export training datasets in the UI, improving default display settings, adding per-class filtering and analysis, and several other great enhancements for easier integration with larger ML pipelines.
Some of the models offer capabilities for you to fine-tune them with your own data. SageMaker JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for machine learning (ML) with SageMaker. Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services.
Enhanced user experience in Snorkel Flow Studio We’ve made significant improvements to Snorkel Flow Studio, making it easier for you to export training datasets in the UI, improving default display settings, adding per-class filtering and analysis, and several other great enhancements for easier integration with larger ML pipelines.
To read more about LLMOps and MLOps, checkout the O’Reilly book “Implementing MLOps in the Enterprise” , authored by Iguazio ’s CTO and co-founder Yaron Haviv and by Noah Gift. They are characterized by their enormous size, complexity, and the vast amount of data they process. What is LLMOps? Collecting feedback for further tuning.
An updated ML from scratch course will be released. - Do Kaggle's intro and intermediate ML courses to learn more datapreparation with Pandas. Useful books referenced: Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow, Machine Learning Yearning by Andrew Ng. Helps build portfolio and CV.
An updated ML from scratch course will be released. - Do Kaggle's intro and intermediate ML courses to learn more datapreparation with Pandas. Useful books referenced: Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow, Machine Learning Yearning by Andrew Ng. Helps build portfolio and CV.
At the beginning of my machine learning journey, I was convinced that creating an ML model always looks similar. You start with a business problem, prepare a dataset, and finally train the model, which is evaluated and deployed. But most real-world machine learning (ML) projects are not like that. What is continual learning?
It provides a collection of pre-trained models that you can deploy quickly and with ease, accelerating the development and deployment of machine learning (ML) applications. Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on.
Vertex AI provides a suite of tools and services that cater to the entire AI lifecycle, from datapreparation to model deployment and monitoring. Book a demo today. Dr. Ali Arsanjani is the director of AI/ML partner engineering at Google Cloud. See what Snorkel option is right for you.
Vertex AI provides a suite of tools and services that cater to the entire AI lifecycle, from datapreparation to model deployment and monitoring. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
Recently as I focused more on how to make proper data science projects that would be better fit for production, I started to pick up various tools and practices and figured out which were the best for me. However, for the intent of this article, I will strictly follow this principle as demonstrated by the book mentioned above.
Source: Author Introduction Just like having a massive pile of books won't make you a genius unless you read and understand them, a mountain of data won't make a powerful AI if it's not properly labeled. Now you might be wondering, why exactly we need these annotation tools when we can label the MLdata on our own.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
AWS innovates to offer the most advanced infrastructure for ML. For ML specifically, we started with AWS Inferentia, our purpose-built inference chip. Neuron plugs into popular ML frameworks like PyTorch and TensorFlow, and support for JAX is coming early next year. Customers like Adobe, Deutsche Telekom, and Leonardo.ai
The machine learning (ML) model classifies new incoming customer requests as soon as they arrive and redirects them to predefined queues, which allows our dedicated client success agents to focus on the contents of the emails according to their skills and provide appropriate responses.
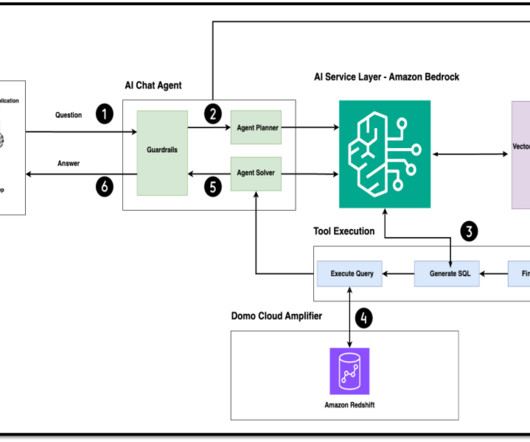
The next step is to provide them with a more intuitive and conversational interface to interact with their data, empowering them to generate meaningful visualizations and reports through natural language interactions. Outside of work, he enjoys playing lawn tennis and reading books. powered by Amazon Bedrock Domo.AI
They can engage users in natural dialogue, provide customer support, answer FAQs, and assist with booking or shopping decisions. Data Management Costs Data Collection : Involves sourcing diverse datasets, including multilingual and domain-specific corpora, from various digital sources, essential for developing a robust LLM.
Let us now look at the key differences starting with their definitions and the type of data they use. Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. In this case, every data point has both input and output values already defined.
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. To further enrich the dataset, Fastweb generated synthetic Italian data using LLMs. The team opted for fine-tuning on AWS.
Solution overview SageMaker JumpStart is a robust feature within the SageMaker machine learning (ML) environment, offering practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs). Choose Submit to start the training job on a SageMaker ML instance. Accept the Llama 3.2
Amber Roberts, Staff Technical Marketing Manager at Databricks Prior to her time at Databricks, Amber was the ML Growth Lead at Arize AI, where she leaned on her years of experience building models as a data scientist and machine learning engineer. Session 2: Machine Learning withCatBoost This workshop will show how to use CatBoost.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







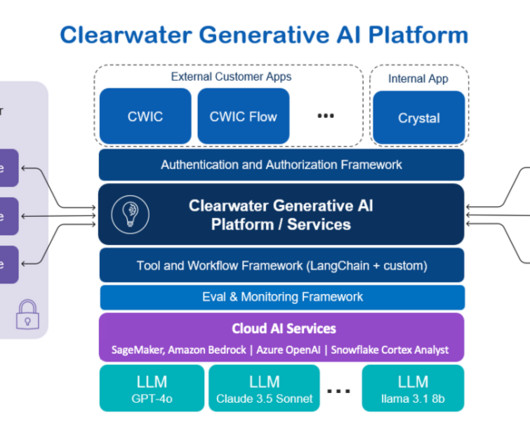






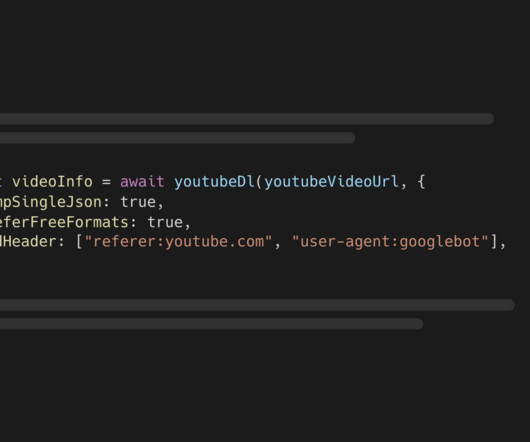
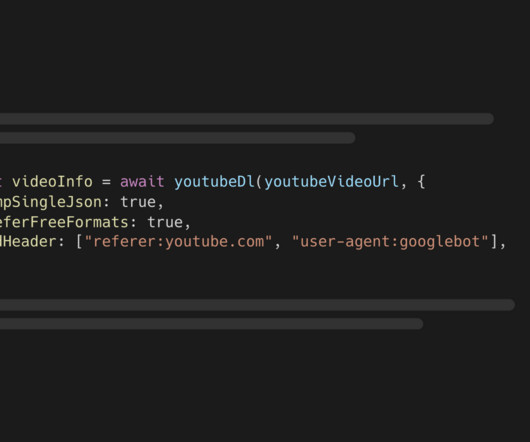

















Let's personalize your content