This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Master LLMs & Generative AI Through These Five Books This article reviews five key books that explore the rapidly evolving fields of large language models (LLMs) and generative AI, providing essential insights into these transformative technologies.
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications. Sonnet across various tasks.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific entities or phrases. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author.
You marked your calendars, you booked your hotel, and you even purchased the airfare. In this code talk, learn how to preparedata at scale using built-in datapreparation assistance, co-edit the same notebook in real time, and automate conversion of notebook code to production-ready jobs. We’ll see you there!
Haystack FileConverters and PreProcessor allow you to clean and prepare your raw files to be in a shape and format that your naturallanguageprocessing (NLP) pipeline and language model of choice can deal with. An indexing pipeline may also include a step to create embeddings for your documents.
The benchmark used is the RoBERTa-Base, a popular model used in naturallanguageprocessing (NLP) applications, that uses the transformer architecture. Any of these parsing steps that run in parallel could be sped up relative to sequential processing.
Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo. For step-by-step instructions, refer to the GitHub repo. SageMaker JumpStart is at the center of this solution.
Source: Author Introduction Just like having a massive pile of books won't make you a genius unless you read and understand them, a mountain of data won't make a powerful AI if it's not properly labeled. Apart from support for various data types, a tool should also be versatile in terms of support for different annotation types.
Google’s thought leadership in AI is exemplified by its groundbreaking advancements in native multimodal support (Gemini), naturallanguageprocessing (BERT, PaLM), computer vision (ImageNet), and deep learning (TensorFlow). Book a demo today. See what Snorkel option is right for you.
Google’s thought leadership in AI is exemplified by its groundbreaking advancements in native multimodal support (Gemini), naturallanguageprocessing (BERT, PaLM), computer vision (ImageNet), and deep learning (TensorFlow). See what Snorkel can do to accelerate your data science and machine learning teams.
Chip Huyen, in her excellent book “ Designing Machine Learning Systems ,” distinguishes four stages of advancement: Manual, stateless retraining : There is no automation. through Cron ), and the whole pipeline (datapreparation, training) is automated. There is no incremental training and no continual learning.
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail.
Introduction Large Language Models (LLMs) represent the cutting-edge of artificial intelligence, driving advancements in everything from naturallanguageprocessing to autonomous agentic systems. Advanced mathematical approaches and architectures have significantly enhanced LLMs' capabilities.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. This fine-tuning process involves providing the model with a dataset specific to the target domain. Person1#: So, how do you create your heroes?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









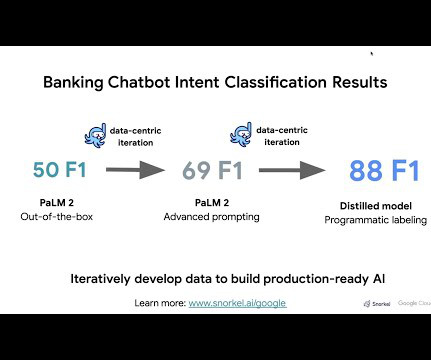











Let's personalize your content