This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data. Amazon Rekognition – This image and video analysis service uses ML to extract metadata from visual data.
You marked your calendars, you booked your hotel, and you even purchased the airfare. Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. To help you plan your agenda for this year’s re:Invent, here are some highlights of the generative AI and ML track.
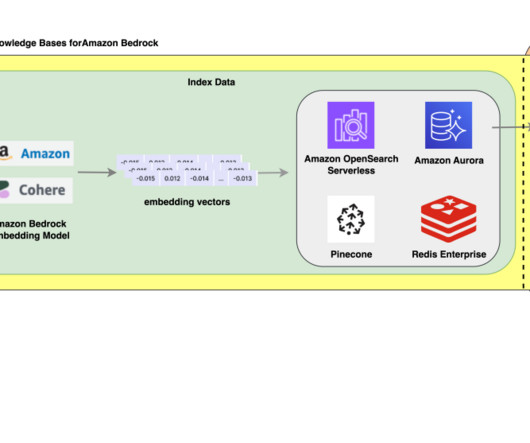
The following diagram illustrates how RBAC works with metadata filtering in the vector database. Amazon Bedrock Knowledge Bases performs similarity searches on the OpenSearch Service vector database and retrieves relevant chunks (optionally, you can improve the relevance of query responses using a reranker model in the knowledge base).
Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for data scientists and ML engineers to build, train, deploy, and manage machine learning models at scale. You can explore its capabilities through the official Azure ML Studio documentation. Awesome, right?
What do machine learning engineers do: ML engineers design and develop machine learning models The responsibilities of a machine learning engineer entail developing, training, and maintaining machine learning systems, as well as performing statistical analyses to refine test results. Is ML engineering a stressful job?
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. The transformer is trained on a large database of text, such a database is called a “corpus”.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. The transformer is trained on a large database of text, such a database is called a “corpus”.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
Many of you asked for an electronic version of our new book, so after working out the kinks, we are finally excited to release the electronic version of “Building LLMs for Production.” We’ve heard many feedback from you guys wanting to have both the e-book and book for different occasions. We listened.
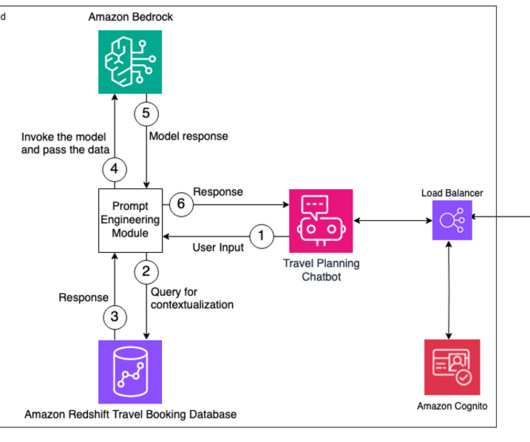
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. This solution contains two major components. This solution contains two major components.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies.
TL;DR Vector databases play a key role in Retrieval-Augmented Generation (RAG) systems. Further, talking to data scientists and ML engineers, I noticed quite a bit of confusion around RAG systems and terminology. Vector Database: A database purpose-built for handling storage and retrieval of vectors.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
The following is an extract from Andrew McMahon’s book , Machine Learning Engineering with Python, Second Edition. Secondly, to be a successful ML engineer in the real world, you cannot just understand the technology; you must understand the business. First of all, the ultimate goal of your work is to generate value.
They’ve long used AI’s little brother Machine Learning (ML) for demand and price management in the airline, hotel, and transport industries. ML and AI are already working to benefit travel companies Online travel platforms and service providers have been using ML for years, even if travelers aren’t aware of this. AI is (merely!)
Embeddings play a key role in natural language processing (NLP) and machine learning (ML). This technique is achieved through the use of ML algorithms that enable the understanding of the meaning and context of data (semantic relationships) and the learning of complex relationships and patterns within the data (syntactic relationships).
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. Scott Fitzgerald.
The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
It’s in every book, on-demand course, and video, and will eventually be available across our entire learning platform. Answers enables active learning: interacting with content by asking questions and getting answers, rather than simply ingesting a stream from a book or video. With RAG, adding content is trivial.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The generated query is then run against the database to fetch the relevant context. Based on the initial tests, this method showed great results.
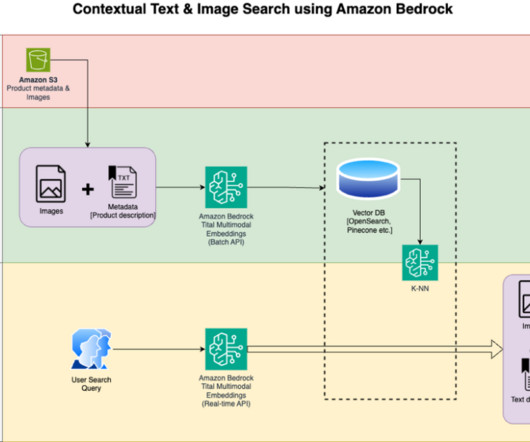
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS.
Welcome to the wild, wacky world of databases! But with so many types of databases to choose from, how do you know which one is right for you? Databases are like different tools in a toolbox — each designed for a different need Picture a toolbox filled with different tools, each designed for a specific task. and let’s dive in!
Learn about the most exciting advancements in ML, NLP, and robotics and how they are being scaled for success and growth. Featured Community post from the Discord Danieldanieldaniel1 wrote an article on building a local-first vector database using RxDB and transformers.js. Learn AI Together Community section! AI poll of the week!
Large language models are powerful AI-powered language tools trained on massive amounts of text data, like books, articles, and even code. Hence, embeddings take on the role of a translator, making words comprehendible for ML models. Here’s a video series providing a comprehensive exploration of embeddings and vector databases.
Amazon Monitron is an end-to-end condition monitoring solution that enables you to start monitoring equipment health with the aid of machine learning (ML) in minutes, so you can implement predictive maintenance and reduce unplanned downtime. For the detailed Amazon Monitron installation guide, refer to Getting started with Amazon Monitron.
Current security recommendations in this area involve defining IAM controls, multiple ways to implement detective controls on databases, strengthening infrastructure security surrounding your data via network flow control, and data protection through encryption and tokenization. His interests include serverless architectures and AI/ML.
Solid theoretical background in statistics and machine learning, experience with state-of-the-art deep learning algorithms, expert command of tools for data pre-processing, database management and visualisation, creativity and story-telling abilities, communication and team-building skills, familiarity with the industry.
Knowledge Bases is completely serverless, so you don’t need to manage any infrastructure, and when using Knowledge Bases, you’re only charged for the models, vector databases and storage you use. In the Vector database section, select Quick create a new vector store , which manages the process of setting up a vector store. Choose Next.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data scientist experience In this section, we cover how data scientists can connect to Snowflake as a data source in Data Wrangler and prepare data for ML. Choose Open Studio.
The new Amazon Relational Database Service (Amazon RDS) for Db2 offering allows customers to migrate their existing, self-managed Db2 databases to the cloud and accelerate strategic modernization initiatives. Are there any constraints on the number of databases that can be hosted on an instance? Scalability 5. . Amazon RDS
ML models are mathematical models and therefore require numerical data. Vectors are typically stored in Vector Databases which are best suited for searching. APIs File Directories Databases And many more The first step is to extract the information present in these source locations. What is a Vector Database?
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. In recent years, ML techniques have become increasingly popular to enhance search.
Photo by Zbynek Burival on Unsplash Time series forecasting is a specific machine learning (ML) discipline that enables organizations to make informed planning decisions. Amazon has a long heritage of using time series forecasting, dating back to the early days of having to meet mail-order book demand.
Agents extend FMs to run complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without writing any code. You can perform a variety of tasks, including sending email notifications, writing to databases, and triggering application APIs in the Lambda functions.
During the last 18 months, we’ve launched more than twice as many machine learning (ML) and generative AI features into general availability than the other major cloud providers combined. Customers can co-locate vector data with operational data, reducing the overhead of managing another database.
The BigBasket team was running open source, in-house ML algorithms for computer vision object recognition to power AI-enabled checkout at their Fresho (physical) stores. Their objective was to fine-tune an existing computer vision machine learning (ML) model for SKU detection. Split data into train, validation, and test sets.
IDP is an industry term used for describing the mechanism for processing and extracting information out of structured, semi-structured, and unstructured documents using AI and machine learning (ML). The transformed data is then tailored to match the formats required by their downstream databases.
Context is retrieved from the vector database based on the user query. For example, consider the following query: What is the cost of the book " " on ? In this query for a book name and website name, a keyword search will give better results, because we want the cost of the specific book.
All resources listed here are free, except some online courses and books, which are recommended for a better understanding. If you’re passionate about ML and interested in collaborative learning, connect in the thread! It is intended for anyone with a small programming and machine learning background.
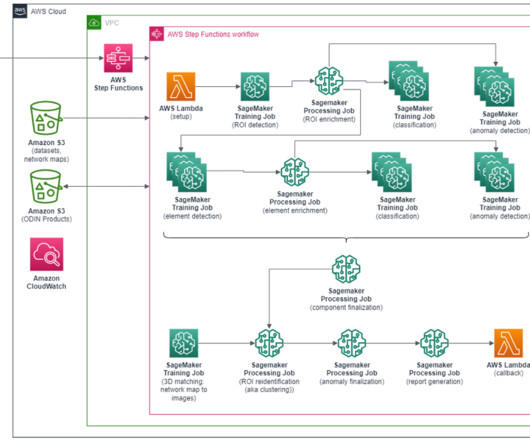
In recent years, the company has invested heavily in the machine learning (ML) sector by developing strong in-house know-how that has enabled them to realize very ambitious projects such as automatic monitoring of its 2.3 The following is a high-level architecture of the ML pipeline with its main steps. GW of installed capacity.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. The union of advances in hardware and ML has led us to the current day.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content