This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
How to use AI to write a book? Here, we’ll explore how AI is not just a tool for efficiency but a collaborator in the creative process, offering unique opportunities for aspiring and seasoned authors alike. How to use AI to write a book? This involves defining the concept and genre of your book.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). It was like reading a book in every possible sequence to grasp every nuance.
These steps will guide you through deleting your knowledge base, vector database, AWS Identity and Access Management (IAM) roles, and sample datasets, making sure that you don’t incur unexpected costs. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI.
An example multi-hop query in finance is Compare the oldest booked Amazon revenue to the most recent. With AWS, you have access to scalable infrastructure and advanced services like Amazon Neptune , a fully managed graph database service. Implementing GraphRAG from scratch usually requires a process similar to the following diagram.
Learn NLP data processing operations with NLTK, visualize data with Kangas , build a spam classifier, and track it with Comet Machine Learning Platform Photo by Stephen Phillips — Hostreviews.co.uk on Unsplash At its core, the discipline of NaturalLanguageProcessing (NLP) tries to make the human language “palatable” to computers.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning algorithms. The transformer is trained on a large database of text, such a database is called a “corpus”.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. The transformer is trained on a large database of text, such a database is called a “corpus”.
Most paraphrasing tools that are powered by AI are developed using Python because Python has a lot of prebuilt libraries for NLP ( naturallanguageprocessing ). NLP is yet another application of machine learning. The transformer is trained on a large database of text, such a database is called a “corpus”.
Imagine a computer program that’s a whiz with words, capable of understanding and using language in fascinating ways. Large language models are powerful AI-powered language tools trained on massive amounts of text data, like books, articles, and even code. That’s essentially what an LLM is!
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. The example matches a user’s query to the closest entries in an in-memory vector database.
This includes blog posts, e-books, research papers, and more. It boasts a rich database of video clips and a meticulously trained language model, allowing customization through voice commands and seamless integration with various social media platforms. Signing up or logging into your account.
Automated bookingprocesses : Travel bookings can be automated to reduce errors with expanded, all-in-one transaction chains for connecting flights, seamless transport, sightseeing trips, and accommodation. Now, AI enables them to integrate any number of other factors that might play a role in forecasts.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. Amazon Connect forwards the user’s message to Amazon Lex for naturallanguageprocessing.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. Scott Fitzgerald.
The CloudFormation template provisions resources such as Amazon Data Firehose delivery streams, AWS Lambda functions, Amazon S3 buckets, and AWS Glue crawlers and databases. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The idea was to use the LLM to first generate a SQL statement from the user question, presented to the LLM in naturallanguage.
Trained with 570 GB of data from books and all the written text on the internet, ChatGPT is an impressive example of the training that goes into the creation of conversational AI. They are designed to understand and generate human-like language by learning from a large dataset of texts, such as books, articles, and websites.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). It can analyze text in multiple languages, detect entities, extract key phrases, determine sentiment, and more.
For RAG-based applications, the accuracy of the generated response from large language models (LLMs) is dependent on the context provided to the model. Context is retrieved from the vector database based on the user query. For example, consider the following query: What is the cost of the book " " on ?
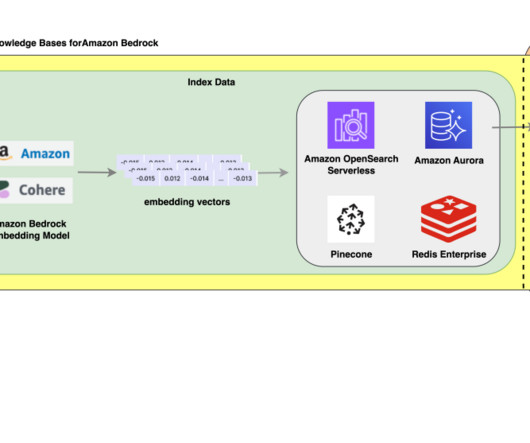
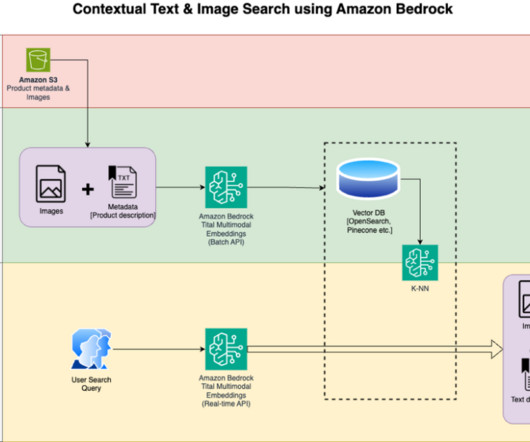
With Amazon Titan Multimodal Embeddings, you can generate embeddings for your content and store them in a vector database. We use Amazon OpenSearch Serverless as a vector database for storing embeddings generated by the Amazon Titan Multimodal Embeddings model. These steps are completed prior to the user interaction steps.
The platform enables you to create managed agents for complex business tasks without the need for coding, such as booking travel, processing insurance claims, creating ad campaigns, and managing inventory. AWS Lambda – AWS Lambda provides serverless compute for processing. This could be any database of your choice.
I used this foolproof method of consuming the right information and ended up publishing books , artworks , Podcasts and even an LLM powered consumer facing app ranked #40 on the app store. YouTube Introduction to NaturalLanguageProcessing (NLP) NLP 2012 Dan Jurafsky and Chris Manning (1.1)
With over 4 million hosts and more than 1 billion guest arrivals since its inception, the platform collects data from various sources, including user interactions, booking patterns, and customer feedback. They can include databases, flat files, APIs, and live data streams.
In this post, we demonstrate how you can build chatbots with QnAIntent that connects to a knowledge base in Amazon Bedrock (powered by Amazon OpenSearch Serverless as a vector database ) and build rich, self-service, conversational experiences for your customers.
Internally, Amazon Bedrock uses embeddings stored in a vector database to augment user query context at runtime and enable a managed RAG architecture solution. Retrieval Augmented Generation RAG is an approach to naturallanguage generation that incorporates information retrieval into the generation process. Choose Next.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific entities or phrases. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author.
It’s possible to augment this basic process with OCR so the application can find data on paper forms, or to use naturallanguageprocessing to gather information through a chat server. But the core of the process is simple, and hasn’t changed much since the early days of web testing. That’s the bad news.
Booked: Date the stay was booked. They are particularly important for generative AI (GenAI) tasks such as naturallanguageprocessing, question answering, and content generation. However, tools utilizing naturallanguageprocessing might have difficulty determining what some columns refer to without a little help.
Knowledge Bases is completely serverless, so you don’t need to manage any infrastructure, and when using Knowledge Bases, you’re only charged for the models, vector databases and storage you use. RAG is a popular technique that combines the use of private data with large language models (LLMs). md) HyperText Markup Language (.html)
This is a guest post by Wah Loon Keng , the author of spacy-nlp , a client that exposes spaCy ’s NLP text parsing to Node.js (and other languages) via Socket.IO. NaturalLanguageProcessing and other AI technologies promise to let us build applications that offer smarter, more context-aware user experiences. CLI: 2.4.0,
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Machine learning provides the technical basis for data mining.
You marked your calendars, you booked your hotel, and you even purchased the airfare. Embeddings can be stored in a database and are used to enable streamlined and more accurate searches. Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! You must bring your laptop to participate. We’ll see you there!
The final retrieval augmentation workflow covers the following high-level steps: The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
We’ve booked an appointment for you tomorrow, September 4th, 2024, at 2pm. The following is an example ambiguous prompt Check if the user has time off available and book it if possible. Always confirm with the user before finalizing any time-off bookings. vacation booking, policy questions) and edge cases (e.g.,
Advanced RAG Scenarios: Building Your Own Database Agents Adrián González Sánchez | Data & AI Specialist at Microsoft | Book Author | LinkedIn Learning & DeepLearning.ai
It also includes requests for text translation, summarization, or explicit inquiries about the meaning of words or sentences in a specific language. Document_Translation class This class is characterized by requests for the translation of a document to a specific language.
You have a specific book in mind, but you have no idea where to find it. You enter the title of the book into the computer and the library’s digital inventory system tells you the exact section and aisle where the book is located. Technical metadata to describe schemas, indexes and other database objects.
To DIY you need to: host an API, build a UI, and run or rent a database. Spotify | SoundCloud | Apple Video of the Week: Towards Explainable and Language-Agnostic LLMs In this talk, Walid S. Spotify | SoundCloud | Apple Video of the Week: Towards Explainable and Language-Agnostic LLMs In this talk, Walid S.
Usually, when a new entry for an inbound client is formed, an email is sent to greet them and to introduce the suggestion of booking a product demo. Automate and customize interactions: Take advantage of the information you’ve gathered in your customer database to nurture leads and increase revenue. Handle RFP generation.
In our review of 2019 we talked a lot about reinforcement learning and Generative Adversarial Networks (GANs), in 2020 we focused on NaturalLanguageProcessing (NLP) and algorithmic bias, in 202 1 Transformers stole the spotlight. Just wait until you hear what happened in 2022. What happened?
It provides a comprehensive and flexible platform that enables developers to integrate language models like GPT, BERT, and others into various applications. By offering modular tools, LangChain facilitates the creation, management, and deployment of sophisticated naturallanguageprocessing (NLP) systems with minimal effort.
There is no doubt this powerful AI model becoming so popular and has opened up new possibilities for naturallanguageprocessing applications, enabling developers to create more sophisticated, human-like interactions in chatbots, question-answering systems, summarization tools, and beyond.
The following criteria governed our search for the best AI checker for essays and other forms of material created by AI tools: AI integration Database size Effectiveness in identifying plagiarized work even when it has been paraphrased. But it is not the only spec that we are taking into account. For more information, click here.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content