This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Empowering Startups and Entrepreneurs | InvestBegin.com | investbegin The success of ChatGPT can be attributed to several key factors, including advancements in machine learning, naturallanguageprocessing, and big data. NLP is a field of AI that focuses on enabling computers to understand and process human language.
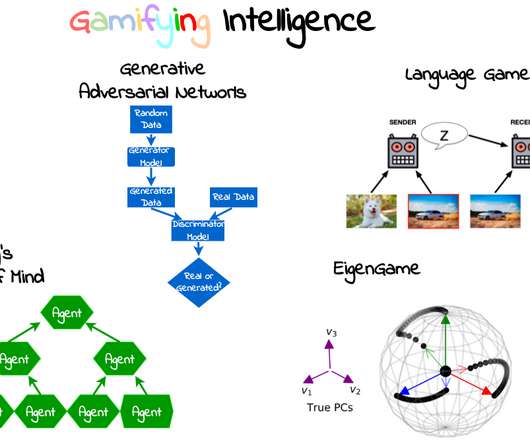
. ⁍ Preface In 1986, Marvin Minsky , a pioneering computer scientist who greatly influenced the dawn of AI research, wrote a book that was to remain an obscure account of his theory of intelligence for decades to come. Language as a game: the field of Emergent Communication Firstly, what is language?
Data mining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). The former is a term used for models where the data has been labeled, whereas, unsupervised learning, on the other hand, refers to unlabeled data. Classification. Regression.
Trained with 570 GB of data from books and all the written text on the internet, ChatGPT is an impressive example of the training that goes into the creation of conversational AI. ChatGPT is a next-generation language model (referred to as GPT-3.5) They can be used to generate news articles, stories, poems, and even code.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and naturallanguageprocessing (NLP) (understanding and generating text) with a high degree of accuracy.
Question-Answering Question-answering (QA) LLMs are a type of large language model that has been trained specifically to answer questions. They are trained on massive datasets of text and code, including text from books, articles, and code repositories. One common approach is to use supervisedlearning.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). His specialty is NaturalLanguageProcessing (NLP) and is passionate about deep learning.
Diverse career paths : AI spans various fields, including robotics, NaturalLanguageProcessing , computer vision, and automation. For example, You can learn Python on Pickl.AI Books : “Automate the Boring Stuff with Python” is excellent for those who prefer self-paced learning.
So the model is able to generate a poem about quantum physics because it has seen books about quantum physics and poems and is, therefore, able to generate a sequence that is both a probable explanation of quantum physics and a probable poem. In this model, the authors used explicit unified prompts such as “summarize:” to train the model.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. During the training process, the model accepts sequences of words with one or more words missing. The model then predicts the missing words (see “what is self-supervisedlearning?”
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervisedlearning. During the training process, the model accepts sequences of words with one or more words missing. The model then predicts the missing words (see “what is self-supervisedlearning?”
A more formal definition of text labeling, also known as text annotation, would be the process of adding meaningful tags or labels to raw text to make it usable for machine learning and naturallanguageprocessing tasks. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, NaturalLanguageProcessing , Statistics and Mathematics. These are a few online tutorials, instructions, and books available that can help you with comprehending these basic concepts.
What Are Large Language Models? Large Language Models are deep learning models that recognize, comprehend, and generate text, performing various other naturallanguageprocessing (NLP) tasks. At its core, machine learning is about finding and learning patterns in data that can be used to make decisions.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. But when you take a lot of these very difficult exams, they’re open book exams. And, when you do your job, you can always go back to the book or to the internet and ask questions.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. But when you take a lot of these very difficult exams, they’re open book exams. And, when you do your job, you can always go back to the book or to the internet and ask questions.
However, if architectural or memory-based approaches are available, the regularization-based techniques are widely used in many continual learning problems more as quickly delivered baselines rather than final solutions. Continuum is a library providing tools for creating continual learning scenarios from existing datasets.
Tools like LangChain , combined with a large language model (LLM) powered by Amazon Bedrock or Amazon SageMaker JumpStart , simplify the implementation process. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content