This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon This. The post Automated Machine Learning for SupervisedLearning (Part 1) appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction This article will talk about Logistic Regression, a method for. The post Logistic Regression- SupervisedLearning Algorithm for Classification appeared first on Analytics Vidhya.
Primary SupervisedLearning Algorithms Used in Machine Learning; Top 15 Books to Master Data Strategy; Top Data Science Podcasts for 2022; Prepare Your Data for Effective Tableau & Power BI Dashboards; Generate Synthetic Time-series Data with Open-source Tools.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. SUPERVISEDLEARNING Before making you understand the broad category of. The post Understanding Supervised and Unsupervised Learning appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Machine learning algorithms are classified into three types: supervisedlearning, The post K-Means Clustering Algorithm with R: A Beginner’s Guide. appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Linear Regression Linear Regression is a supervisedlearning technique that involves. The post A Walk-through of Regression Analysis Using Artificial Neural Networks in Tensorflow appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Speech Recognition is a supervisedlearning task. In the speech. The post MFCC Technique for Speech Recognition appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Regression is a supervisedlearning technique that supports finding the. The post Linear Regression in machine learning appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Objective The main objective of this article is to understand what. The post Parkinson disease onset detection Using Machine Learning! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction This article aims to explain deep learning and some supervised. The post Introduction to Supervised Deep Learning Algorithms! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. The post K-Nearest Neighbour: The Distance-Based Machine Learning Algorithm. Introduction The abbreviation KNN stands for “K-Nearest Neighbour” It is. appeared first on Analytics Vidhya.
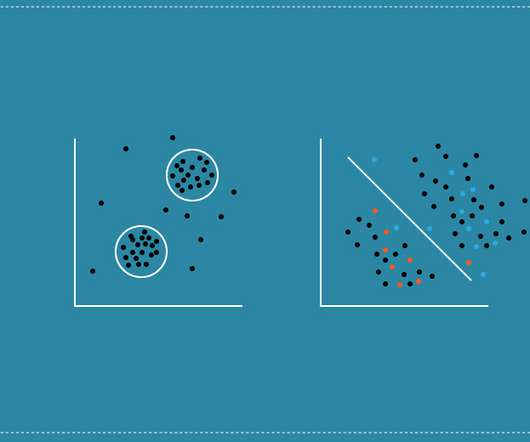
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
Model selection and training: Teaching machines to learn With your data ready, it’s time to select an appropriate ML algorithm. Popular choices include: Supervisedlearning algorithms like linear regression or decision trees for problems with labeled data.
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Transfer learning and better annotation tooling are both key to our current plans for spaCy and related projects.
This function can be improved by AI and ML, which allow GIS to produce insights, automate procedures, and learn from data. Types of Machine Learning for GIS 1. Supervisedlearning– In supervisedlearning, the input data and associated output labels are paired, letting the system be trained on labelled data.
High school teachers are learning the same. A ChatGPT-written book report or historical essay may be a breeze to read but could easily contain erroneous facts that the student was too lazy to root out. Hallucinations are a serious problem.
For instance, for culture, we have a set of embeddings for sports, TV programs, music, books, and so on. In a traditional classification system, wed be required to train a classifiera supervisedlearning task where wed need to provide a series of examples to establish whether an article belongs to its respective topic.
Best Practices for Azure Machine Learning Projects To get the most out of Azure Machine Learning, consider these best practices: Data Management Use Azure Data Stores : Connect to various data sources including Azure Blob Storage, Azure Data Lake, and Azure SQL Database for efficient data access. Happy modeling, friends!
List of common data modalities in AI Primary modalities commonly involved in AI include: Text : This includes any form of written language, such as articles, books, social media posts, and other textual data. Images : This involves visual data, including photographs, drawings, and any kind of visual representation in digital form.
Since the 1950s, teenage boys around the world have expressed an interest in robots after reading books by Isaac Asimov and other science fiction writers. There are a number of different ways that robots can learn and improve their functionality. One approach is imitation learning. Self-supervisedlearning is also a possibility.
Learning Resources To master Python for Data Science, accessing high-quality learning resources catering to beginners and professionals is essential. From structured online courses to insightful books and tutorials and engaging YouTube channels and podcasts, a wealth of content guides you on your journey.
Machine Learning Best Practices for Downloaded Videos Once you’ve downloaded your videos using Y2Mate, here are some ML-specific tips: Data Preprocessing : Convert videos to frame sequences for computer vision tasks Augmentation : Generate additional training samples through rotation, cropping, etc.
Large language models A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervisedlearning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks.
Ive also noticed this issue extends to resources like courses and books you complete one, and suddenly, theres another skill youre missing. What if you learned how to teach yourself using the most powerful AI tools instead of relying on courses forever? But what if you could break that cycle?
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Classification. Regression.
ChatGPT was trained using a process called unsupervised learning, which means that it was not given specific instructions on how to interpret the data. Instead, the model was left to find its own patterns and relationships within the data, using a process known as self-supervisedlearning.
. ⁍ Preface In 1986, Marvin Minsky , a pioneering computer scientist who greatly influenced the dawn of AI research, wrote a book that was to remain an obscure account of his theory of intelligence for decades to come. The Society of Mind consisted of 270 essays divided into 30 chapters.
There are two types of machine learning based on the data on which the experts are training the model: SupervisedLearning: It is used when we have training data with the labels for the correct answer. For more awesome content, check our book reviews and courses bellow! Deep Learning with Python by Francois Chollet.
Primary modalities commonly involved in AI include: Text : This includes any form of written language, such as articles, books, social media posts, and other textual data. In the context of Artificial Intelligence (AI), a modality refers to a specific type or form of data that can be processed and understood by AI models.
They can also perform self-supervisedlearning to generalize and apply their knowledge to new tasks. Instead of spending time and effort on training a model from scratch, data scientists can use pretrained foundation models as starting points to create or customize generative AI models for a specific use case.
We have begun to observe diminishing returns and are already exploring other promising research directions into multimodality and self-supervisedlearning. While this progress has been exciting, bootstrapping strong teacher models was bound to run into an asymptotic limit and stop bearing fruit. Panayotov, G. Povey and S.
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” Let’s go back to our history book analogy. That’s how RAG works.
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. Data scientists train embedding models on unstructured text through a process called “self-supervisedlearning.” Let’s go back to our history book analogy. That’s how RAG works.
Trained with 570 GB of data from books and all the written text on the internet, ChatGPT is an impressive example of the training that goes into the creation of conversational AI. They are designed to understand and generate human-like language by learning from a large dataset of texts, such as books, articles, and websites.
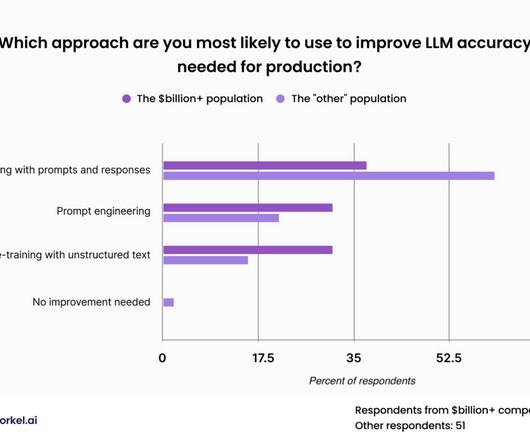
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
It is trained on a large dataset of diverse long videos and books using RingAttention and can perform language, image, and video understanding and generation. REGISTER NOW Trending New Open Source Projects Large World Model (LWM) is a general-purpose large-context multimodal autoregressive model.
They are trained on massive datasets of text and code, including text from books, articles, and code repositories. This allows them to learn the statistical relationships between words and phrases, and to understand the meaning of questions and answers. One common approach is to use supervisedlearning.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervisedlearning (SSL). His specialty is Natural Language Processing (NLP) and is passionate about deep learning.
Data Analysis When working with data, especially supervisedlearning, it is often a best practice to check data imbalance. Download the Source Code and FREE 17-page Resource Guide Enter your email address below to get a.zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.
.” So let’s say we’ve got the text “ The best thing about AI is its ability to ” Imagine scanning billions of pages of human-written text (say on the web and in digitized books) and finding all instances of this text—then seeing what word comes next what fraction of the time. written by humans.
So the model is able to generate a poem about quantum physics because it has seen books about quantum physics and poems and is, therefore, able to generate a sequence that is both a probable explanation of quantum physics and a probable poem. In this model, the authors used explicit unified prompts such as “summarize:” to train the model.
Pre-training with unstructured data Pre-training with unstructured data sounds simple: gather proprietary data from across your organization and dump it all into a self-supervisedlearning pipeline. Book a demo today. But it’s not that straightforward. See what Snorkel option is right for you.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content