This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. Which one is right for your business? What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
In today’s digital world, data is king. Organizations that can capture, store, format, and analyze data and apply the businessintelligence gained through that analysis to their products or services can enjoy significant competitive advantages. But, the amount of data companies must manage is growing at a staggering rate.
An interactive analytics application gives users the ability to run complex queries across complex data landscapes in real-time: thus, the basis of its appeal. Interactive analytics applications present vast volumes of unstructured data at scale to provide instant insights. Every organization needs data to make many decisions.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
Data analytics is a task that resides under the data science umbrella and is done to query, interpret and visualize datasets. Datascientists will often perform data analysis tasks to understand a dataset or evaluate outcomes. Those who work in the field of data science are known as datascientists.
Data models help visualize and organize data, processing applications handle large datasets efficiently, and analytics models aid in understanding complex data sets, laying the foundation for businessintelligence. Ensure that data is clean, consistent, and up-to-date.
These days, datascientists are in high demand. Across the country, datascientists have an unemployment rate of 2% and command an average salary of nearly $100,000. For these reasons, finding and evaluating data is often time-consuming. How Data Catalogs Help DataScientists Ask Better Questions.
Connecting AI models to a myriad of data sources across cloud and on-premises environments AI models rely on vast amounts of data for training. Once trained and deployed, models also need reliable access to historical and real-time data to generate content, make recommendations, detect errors, send proactive alerts, etc.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
Business organisations worldwide depend on massive volumes of data that require DataScientists and analysts to interpret to make efficient decisions. Understanding the appropriate ways to use data remains critical to success in finance, education and commerce. are the various data mining tools. Wrapping Up!
Organizations who are so successful in their adoption of self-service analytics, that their own businessintelligence (BI) evangelists worry that they’ve created an analytics “wild west.” When they see a data catalog for the first time, they’re thrilled that a product exists that can govern the west and increase analyst productivity.
Think of it as building plumbing for data to flow smoothly throughout the organization. EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI.
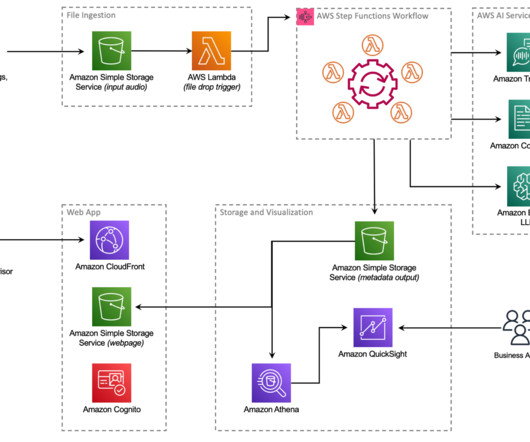
After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other businessintelligence (BI) tools. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Dimensional Data Modeling in the Modern Era by Dustin Dorsey Slides Dustin Dorsey’s AI slides explored the evolution of dimensional data modeling, a staple in data warehousing and businessintelligence.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. ” Vitaly Tsivin, EVP BusinessIntelligence at AMC Networks.
It involves the design, development, and maintenance of systems, tools, and processes that enable the acquisition, storage, processing, and analysis of large volumes of data. Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data.
. Request a live demo or start a proof of concept with Amazon RDS for Db2 Db2 Warehouse SaaS on AWS The cloud-native Db2 Warehouse fulfills your price and performance objectives for mission-critical operational analytics, businessintelligence (BI) and mixed workloads.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling businessintelligence and analytics is growing exponentially, giving birth to cloud solutions. Data warehousing is a vital constituent of any businessintelligence operation.
A modern data catalog is more than just a collection of your enterprise’s every data asset. It’s also a repository of metadata — or data about data — on information sources from across the enterprise, including data sets, businessintelligence reports, and visualizations.
In today’s world, data warehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as businessintelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization.
We have an explosion, not only in the raw amount of data, but in the types of database systems for storing it ( db-engines.com ranks over 340) and architectures for managing it (from operational datastores to datalakes to cloud data warehouses). Organizations are drowning in a deluge of data.
Moving/integrating data in the cloud/data exploration and quality assessment. Once migration is complete, it’s important that your datascientists and engineers have the tools to search, assemble, and manipulate data sources through the following techniques and tools. Support for languages and SQL.
ETL pipeline | Source: Author These activities involve extracting data from one system, transforming it, and then processing it into another target system where it can be stored and managed. ML heavily relies on ETL pipelines as the accuracy and effectiveness of a model are directly impacted by the quality of the training data.
With this service, industrial sensors, smart meters, and OPC UA servers can be connected to an AWS datalake with just a few clicks. Fauzan is passionate about helping customers adopt innovative cloud technologies in the area of HPC and AI/ML to address business challenges. Outside of work, Fauzan enjoys spending time in nature.
It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves data engineers, datascientists, and business analysts using different systems and tools. Personas There are four personas used in this solution.
Data Swamp vs DataLake. When you imagine a lake, it’s likely an idyllic image of a tree-ringed body of reflective water amid singing birds and dabbling ducks. I’ll take the lake, thank you very much. But when it’s dirty, stagnant, or hard to unleash, your business will suffer. Benefits of a DataLake.
Übrigens nicht mehr so stark bei den DataScientists, auch wenn richtig gute Mitarbeiter ebenfalls rar gesät sind, den größten Bedarf haben Unternehmen eher bei den Data Engineers. Das sind die Kollegen, die die Data Warehouses oder DataLakes aufbauen und pflegen. appeared first on Data Science Blog.
Each component contributes to the overall goal of extracting valuable insights from data. Data collection This involves techniques for gathering relevant data from various sources, such as datalakes and warehouses. Accurate data collection is crucial as it forms the foundation for analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content