This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
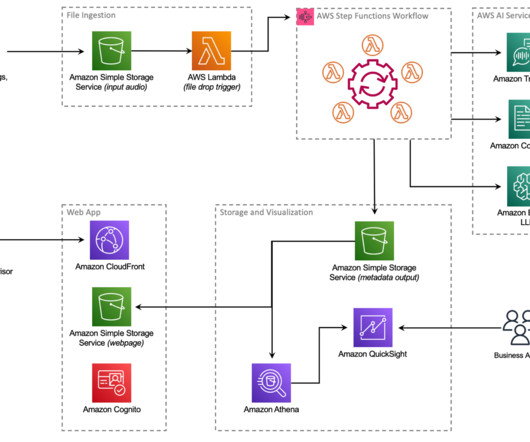
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
An interactive analytics application gives users the ability to run complex queries across complex data landscapes in real-time: thus, the basis of its appeal. Interactive analytics applications present vast volumes of unstructured data at scale to provide instant insights. Amazon Redshift is a fast and widely used data warehouse.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, data scientist, or data analyst.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, datalakes, data warehouses and SQL databases, providing a holistic view into business performance. Then, it applies these insights to automate and orchestrate the data lifecycle.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other businessintelligence (BI) tools. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud data ingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. It’s an easy way to run analytics on IoT data to gain accurate insights.
To create and share customer feedback analysis without the need to manage underlying infrastructure, Amazon QuickSight provides a straightforward way to build visualizations, perform one-time analysis, and quickly gain business insights from customer feedback, anytime and on any device. The Step Functions workflow starts.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machine learning (ML). The development and use of these models explain the enormous amount of recent AI breakthroughs.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and ML engineers to build and deploy models at scale.
. Request a live demo or start a proof of concept with Amazon RDS for Db2 Db2 Warehouse SaaS on AWS The cloud-native Db2 Warehouse fulfills your price and performance objectives for mission-critical operational analytics, businessintelligence (BI) and mixed workloads.
And, as organizations progress and grow, “data drift” starts to impact data usage, models, and your business. In today’s AI/ML-driven world of data analytics, explainability needs a repository just as much as those doing the explaining need access to metadata, EG, information about the data being used.
We use data-specific preprocessing and ML algorithms suited to each modality to filter out noise and inconsistencies in unstructured data. NLP cleans and refines content for text data, while audio data benefits from signal processing to remove background noise. Tools like Unstructured.io
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling businessintelligence and analytics is growing exponentially, giving birth to cloud solutions. Data warehousing is a vital constituent of any businessintelligence operation.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise. IBM watsonx.ai
In today’s world, data warehouses are a critical component of any organization’s technology ecosystem. They provide the backbone for a range of use cases such as businessintelligence (BI) reporting, dashboarding, and machine-learning (ML)-based predictive analytics, that enable faster decision making and insights.
With an open data lakehouse architecture, you can now optimize your data warehouse workloads for price performance and modernize traditional datalakes with better performance and governance for AI. With the right data, you can create a data-driven organization that drives business value and innovation.
What Is a Data Catalog? A data catalog is a centralized storage bank of metadata on information sources from across the enterprise, such as: Datasets. Businessintelligence reports. The data catalog also stores metadata (data about data, like a conversation), which gives users context on how to use each asset.
In a prior blog , we pointed out that warehouses, known for high-performance data processing for businessintelligence, can quickly become expensive for new data and evolving workloads. To effectively use raw data, it often needs to be curated within a data warehouse. Some use case examples will help.
For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance. It uses metadata and data management tools to organize all data assets within your organization.
Having been in business for over 50 years, ARC had accumulated a massive amount of data that was stored in siloed, on-premises servers across its 7 business domains. Using Alation, ARC automated the data curation and cataloging process. “So
By setting up automated policy enforcement and checks, you can achieve cost optimization across your machine learning (ML) environment. The following table provides examples of a tagging dictionary used for tagging ML resources. A reference architecture for the ML platform with various AWS services is shown in the following diagram.
Although generative AI is fueling transformative innovations, enterprises may still experience sharply divided data silos when it comes to enterprise knowledge, in particular between unstructured content (such as PDFs, Word documents, and HTML pages), and structured data (real-time data and reports stored in databases or datalakes).
This pattern creates a comprehensive solution that transforms raw social media data into actionable businessintelligence (BI) through advanced AI capabilities. 3B Instruct Amazon Bedrock, the system provides tailored marketing content that adds business value. By integrating LLMs such as Anthropics Claude 3.5
Microsoft Azure HDInsight Azure HDInsight is a fully-managed cloud service that makes it easy to process Big Data using popular open-source frameworks such as Hadoop, Spark, and Kafka. Key Features : Integration with Microsoft Services : Seamlessly integrates with other Azure services like Azure DataLake Storage.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content