This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. Vector Similarity Search This video explains what vector databases are and how they can be used for vector similarity searches.
By handling these issues, data preprocessing helps pave the way for more reliable and meaningful analysis. Importance of data preprocessing The role of data preprocessing cannot be overstated, as it significantly influences the quality of the dataanalysis process. customer ID vs. customer number).
Summary: The Data Science and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Sources of DataData can come from multiple sources.
Summary: DataAnalysis focuses on extracting meaningful insights from raw data using statistical and analytical methods, while data visualization transforms these insights into visual formats like graphs and charts for better comprehension. Is DataAnalysis just about crunching numbers?
The following steps are involved in pipeline development: Gathering data: The first step is to gather the data that will be used to train the model. For data scrapping a variety of sources, such as online databases, sensor data, or social media. This involves removing any errors or inconsistencies in the data.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Each component in this ecosystem is very important in the data-driven decision-making process for an organization. Data Sources and Collection Everything in data science begins with data. Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping.
It detaches from the complicated and computes heavy transformations to deliver cleandata into lakes and DWHs. . Their data pipelining solution moves the business entity data through the concept of micro-DBs, which makes it the first of its kind successful solution.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
R, on the other hand, is renowned for its powerful statistical capabilities, making it ideal for in-depth DataAnalysis and modeling. SQL is essential for querying relational databases, which is a common task in Data Analytics. Extensive libraries for data manipulation, visualization, and statistical analysis.
We are living in a world where data drives decisions. Data manipulation in Data Science is the fundamental process in dataanalysis. The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data.
On successful authentication, you will be redirected to the data flow page. Browse to locate loan dataset from the Snowflake database Select the two loans datasets by dragging and dropping them from the left side of the screen to the right. You will be redirected to the Okta login screen to enter Okta credentials to authenticate.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy. Introduction Are you a Python enthusiast looking to import data into your code with ease?
Through this process, the data is made very accurate and prepared for analysis. Data wrangling prepares raw data for analysis by cleaning, converting, and manipulating it. It might be a time-consuming operation but it is a necessary stage in dataanalysis.
Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. The choice of approach depends on the impact of missing data on the overall dataset and the specific analysis or model being used.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. Loading the dataset allows you to begin exploring and manipulating the data.
It can be gradually “enriched” so the typical hierarchy of data is thus: Raw data ↓ Cleaneddata ↓ Analysis-ready data ↓ Decision-ready data ↓ Decisions. For example, vector maps of roads of an area coming from different sources is the raw data. Data Intelligence , 2 (1–2), 199–207.
It’s the critical process of capturing, transforming, and loading data into a centralised repository where it can be processed, analysed, and leveraged. Data Ingestion Meaning At its core, It refers to the act of absorbing data from multiple sources and transporting it to a destination, such as a database, data warehouse, or data lake.
Summary: Data scrubbing is identifying and removing inconsistencies, errors, and irregularities from a dataset. It ensures your data is accurate, consistent, and reliable – the cornerstone for effective dataanalysis and decision-making. Overview Did you know that dirty data costs businesses in the US an estimated $3.1
With its intuitive interface, Power BI empowers users to connect to various data sources, create interactive reports, and share insights effortlessly. Optimising Power BI reports for performance ensures efficient dataanalysis. What is Power BI, and how does it differ from other data visualisation tools?
Data Connectivity: Data Source Compatibility: Power BI can connect to a diverse range of data sources including databases, cloud services, spreadsheets, web services, and more. Direct Query and Import: Users can import data into Power BI or create direct connections to databases for real-time dataanalysis.
Data serves as the backbone of informed decision-making, and the accuracy, consistency, and reliability of data directly impact an organization’s operations, strategy, and overall performance. Informed Decision-making High-quality data empowers organizations to make informed decisions with confidence.
By employing ETL, businesses ensure that their data is reliable, accurate, and ready for analysis. This process is essential in environments where data originates from various systems, such as databases , applications, and web services. The key is to ensure that all relevant data is captured for further processing.
Data Science has also been instrumental in addressing global challenges, such as climate change and disease outbreaks. Data Science has been critical in providing insights and solutions based on DataAnalysis. Skills Required for a Data Scientist Data Science has become a cornerstone of decision-making in many industries.
The systems are designed to ensure data integrity, concurrency and quick response times for enabling interactive user transactions. In online analytical processing, operations typically consist of major fractions of large databases. FAQs Which is the correct sequence of data pre-processing?
There are 5 stages in unstructured data management: Data collection Data integration DatacleaningData annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. We get your data RAG-ready.
This approach can be particularly effective when dealing with real-world applications where data is often noisy or imbalanced. Model-centric AI is well suited for scenarios where you are delivered cleandata that has been perfectly labeled. Consider a customer database that has demographic data for every customer.
This approach can be particularly effective when dealing with real-world applications where data is often noisy or imbalanced. Model-centric AI is well suited for scenarios where you are delivered cleandata that has been perfectly labeled. Consider a customer database that has demographic data for every customer.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Understand the Data Sources The first step in data standardization is to identify and understand the various data sources that will be standardized. This includes databases, spreadsheets, APIs, and manual records. This could include internal databases, external APIs, and third-party data providers.
Step 2: Data Gathering Collect relevant historical data that will be used for forecasting. This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., databases, APIs, CSV files). CleaningData: Address any missing values or outliers that could skew results.
The following figure represents the life cycle of data science. It starts with gathering the business requirements and relevant data. Once the data is acquired, it is maintained by performing datacleaning, data warehousing, data staging, and data architecture.
Prescriptive analytics is a branch of data analytics that focuses on advising on optimal future actions based on dataanalysis. Key steps Specifying requirements for the analysis. Identifying appropriate data sources. Organizing and cleaningdata. What is prescriptive analytics?
User dataanalysis Chattermill is made for apps with tons of users, like BlaBlaCar and Uber. This service works with equations and data in spreadsheet form. But it can do what the best visualization tools do: provide conclusions, cleandata, or highlight key information. Meeting minutes from Neuroslav 3.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























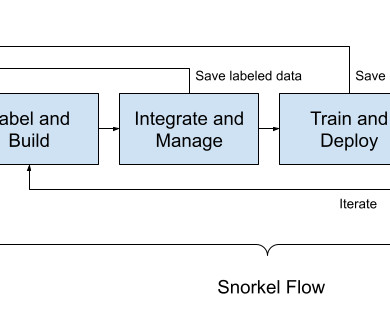
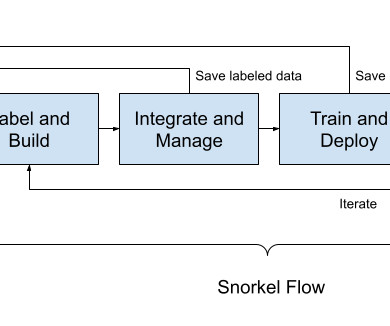












Let's personalize your content