This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Are you curious about what it takes to become a professional data scientist? By following these guides, you can transform yourself into a skilled data scientist and unlock endless career opportunities. Look no further!
In this blog, we will discuss exploratory dataanalysis, also known as EDA, and why it is important. We will also be sharing code snippets so you can try out different analysis techniques yourself. This can be useful for identifying patterns and trends in the data. So, without any further ado let’s dive right in.
This article was published as a part of the Data Science Blogathon Introduction Do you wish you could perform this function using Pandas. For data scientists who use Python as their primary programming language, the Pandas package is a must-have dataanalysis tool. Well, there is a good possibility you can!
Automating datacleaning can speed up […] The post 5-Step Guide to Automate DataCleaning in Python appeared first on Analytics Vidhya. However, this takes up a lot of time, even for experts, as most of the process is manual.
Introduction Python is a versatile and powerful programming language that plays a central role in the toolkit of data scientists and analysts. Its simplicity and readability make it a preferred choice for working with data, from the most fundamental tasks to cutting-edge artificial intelligence and machine learning.
That’s because the machine learning projects go through and process a lot of data, and that data should come in the specified format to make it easier for the AI to catch and process. Likewise, Python is a popular name in the data preprocessing world because of its ability to process the functionalities in different ways.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pandas Pandas is an open-source dataanalysis and data manipulation library. The post Data Manipulation Using Pandas | Essential Functionalities of Pandas you need to know! appeared first on Analytics Vidhya.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in DataAnalysis. It excels in datacleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists.
Photo by Juraj Gabriel on Unsplash Dataanalysis is a powerful tool that helps businesses make informed decisions. In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights. Let’s explore the dataset further by cleaningdata and creating some visualizations.
Summary: The Data Science and DataAnalysis life cycles are systematic processes crucial for uncovering insights from raw data. Quality data is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. Automated systems can extract data from websites or applications.
Summary: DataAnalysis focuses on extracting meaningful insights from raw data using statistical and analytical methods, while data visualization transforms these insights into visual formats like graphs and charts for better comprehension. Is DataAnalysis just about crunching numbers?
Summary: DataAnalysis and interpretation work together to extract insights from raw data. Analysis finds patterns, while interpretation explains their meaning in real life. Overcoming challenges like data quality and bias improves accuracy, helping businesses and researchers make data-driven choices with confidence.
It involves data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and correlations that can drive decision-making. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form. Deployment and Monitoring Once a model is built, it is moved to production.
Empowering Data Scientists and Engineers with Lightning-Fast DataAnalysis and Transformation Capabilities Photo by Hans-Jurgen Mager on Unsplash ?Goal Abstract Polars is a fast-growing open-source data frame library that is rapidly becoming the preferred choice for data scientists and data engineers in Python.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality.
Raw data is processed to make it easier to analyze and interpret. Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. It might be a time-consuming operation but it is a necessary stage in dataanalysis.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
If you do not take your time to clean up this list, then there is every […] The post What is Data Scrubbing? Introduction Think of the fact that you’re planning a massive family gathering. You have a list of attendees, but it is full of wrong contacts, the same contacts and some of the names in the list are spelled wrongly.
Coding Skills for Data Analytics Coding is an essential skill for Data Analysts, as it enables them to manipulate, clean, and analyze data efficiently. Programming languages such as Python, R, SQL, and others are widely used in Data Analytics. Rich set of packages tailored for data manipulation and analysis.
Introduction Are you struggling to decide between data-driven practices and AI-driven strategies for your business? Besides, there is a balance between the precision of traditional dataanalysis and the innovative potential of explainable artificial intelligence.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation.
We are living in a world where data drives decisions. Data manipulation in Data Science is the fundamental process in dataanalysis. The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data.
Individuals with data skills can find a suitable fitment in different industries. Moreover, learning it at a young age can give kids a head start in acquiring the knowledge and skills needed for future career opportunities in DataAnalysis, Machine Learning, and Artificial Intelligence.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. Interprets data to uncover actionable insights guiding business decisions.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Data Science has also been instrumental in addressing global challenges, such as climate change and disease outbreaks. Data Science has been critical in providing insights and solutions based on DataAnalysis. Skills Required for a Data Scientist Data Science has become a cornerstone of decision-making in many industries.
A cheat sheet for Data Scientists is a concise reference guide, summarizing key concepts, formulas, and best practices in DataAnalysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
These may range from Data Analytics projects for beginners to experienced ones. Following is a guide that can help you understand the types of projects and the projects involved with Python and Business Analytics. Here are some project ideas suitable for students interested in big data analytics with Python: 1.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
DataCleaning: Raw data often contains errors, inconsistencies, and missing values. Datacleaning identifies and addresses these issues to ensure data quality and integrity. Data Visualisation: Effective communication of insights is crucial in Data Science.
The following figure represents the life cycle of data science. It starts with gathering the business requirements and relevant data. Once the data is acquired, it is maintained by performing datacleaning, data warehousing, data staging, and data architecture.
Finding the Best CEFR Dictionary This is one of the toughest parts of creating my own machine learning program because cleandata is one of the most important parts. But I have to say that this data is of great quality because we already converted it from messy data into the Python dictionary format that matches our type of work.
Now that you know why it is important to manage unstructured data correctly and what problems it can cause, let's examine a typical project workflow for managing unstructured data. It allows users to extract data from documents, and then you can configure workflows to pass the data downstream to LLMs for further processing.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model.
A Python 3.9+ The following python libraries: comet_ml, Scikit-learn, and Pandas. Project The dataset for my project will be one that might require substantial changes through datacleaning as most real-world datasets would require. They are: A Comet ML account. You can get one here. installation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


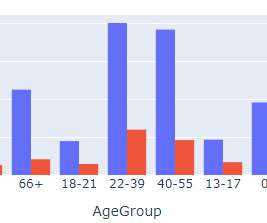













































Let's personalize your content