This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
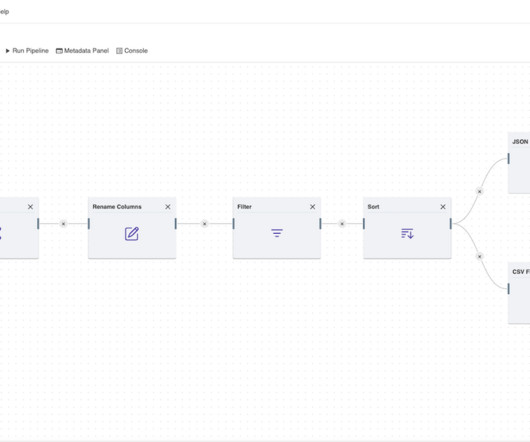
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
Amphi is a micro ETL designed for extracting, preparing and cleaningdata from various sources and formats. Develop datapipelines and generate native Python code you can deploy anywhere.
Hype Cycle for Emerging Technologies 2023 (source: Gartner) Despite AI’s potential, the quality of input data remains crucial. Inaccurate or incomplete data can distort results and undermine AI-driven initiatives, emphasizing the need for cleandata. Cleandata through GenAI!
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines.
Set up a datapipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set. Apache Airflow orchestration provides an easy but powerful solution to integrate DataRobot capabilities into bigger pipelines, combine with other services, cleandata, and store or publish the results.
Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. Tableau’s lightning-fast Google BigQuery connector allows customers to engineer optimized datapipelines with direct connections that power business-critical reporting. Direct connection to Google BigQuery.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. . Tableau’s lightning-fast Google BigQuery connector allows customers to engineer optimized datapipelines with direct connections that power business-critical reporting.
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. Data engineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together.
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
As the algorithms we use have gotten more robust and we have increased our compute power through new technologies, we haven’t made nearly as much progress on the data part of our jobs. Because of this, I’m always looking for ways to automate and improve our datapipelines. So why should we use datapipelines?
Clear Formatting Remove any inconsistent formatting that may interfere with data processing, such as extra spaces or incomplete sentences. Validate Data Perform a final quality check to ensure the cleaneddata meets the required standards and that the results from data processing appear logical and consistent.
Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while data scientists require cleandata for training machine learning models. Without high-quality data, even the most advanced models can't deliver value.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Data Ingestion Tools To facilitate the process, various tools and technologies are available. These tools can automate data collection, transformation, and loading processes, making it easier for organisations to manage their datapipelines effectively. Data Lakes allow for flexible analysis.
Snowpark Use Cases Data Science Streamlining data preparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaningdata directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
Once data is found and cleaned, data scientists and analysts still need to understand the methods by which the data was collected, the limitations on proper use, and any other contextual information that may impact the insights derived from a particular data set. Another limiting factor is that of context.
Step 3: Data Preprocessing and Exploration Before modeling, it’s essential to preprocess and explore the data thoroughly.This step ensures that you have a clean and well-understood dataset before moving on to modeling. CleaningData: Address any missing values or outliers that could skew results.
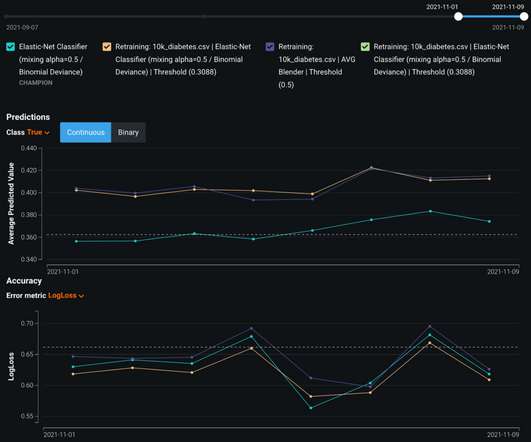
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
Other models should reference the cleaneddata from the staging model rather than the raw source. The dbt project evaluator package highlights areas where your project does not meet the standards set by dbt Labs. To maintain lineage and execution order, replace raw references with ref() or source() functions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content