Open Source Python ETL
Hacker News
JUNE 18, 2024
Amphi is a micro ETL designed for extracting, preparing and cleaning data from various sources and formats. Develop data pipelines and generate native Python code you can deploy anywhere.
 Clean Data Data Pipeline ETL
Clean Data Data Pipeline ETL 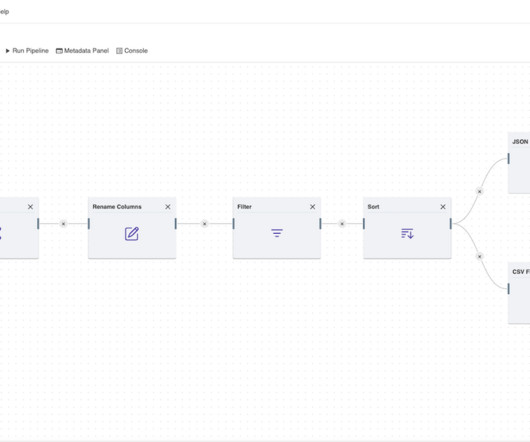
Hacker News
JUNE 18, 2024
Amphi is a micro ETL designed for extracting, preparing and cleaning data from various sources and formats. Develop data pipelines and generate native Python code you can deploy anywhere.

Smart Data Collective
OCTOBER 17, 2022
Data pipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which data pipelines can help address. Choosing the right data pipeline solution.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Pickl AI
JULY 8, 2024
Summary: This blog explains how to build efficient data pipelines, detailing each step from data collection to final delivery. Introduction Data pipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.

Heartbeat
NOVEMBER 6, 2023
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex data pipelines.

Pickl AI
JULY 25, 2024
Data Ingestion Tools To facilitate the process, various tools and technologies are available. These tools can automate data collection, transformation, and loading processes, making it easier for organisations to manage their data pipelines effectively. Data Lakes allow for flexible analysis.

phData
FEBRUARY 7, 2024
Snowpark Use Cases Data Science Streamlining data preparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow data scientists to use familiar tools for wrangling and cleaning data directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.

DagsHub
OCTOBER 23, 2024
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured data pipeline, you can use new entries to train a production ML model, keeping the model up-to-date. Unstructured.io

Expert insights. Personalized for you.





Let's personalize your content