This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI for databases will transform how you deal with databases, whether or not you’re a data scientist, […] The post 10 Ways to Use Generative AI for Database appeared first on Analytics Vidhya. Though it appears to dazzle, its true value lies in refreshing the fundamental roots of applications.
Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. Vector Similarity Search This video explains what vector databases are and how they can be used for vector similarity searches.
INTRODUCTION Hive is one of the most popular data warehouse systems in the industry for data storage, and to store this data Hive uses tables. Tables in the hive are analogous to tables in a relational database management system. Each table belongs to a directory in HDFS. By default, it is /user/hive/warehouse directory.
The following steps are involved in pipeline development: Gathering data: The first step is to gather the data that will be used to train the model. For data scrapping a variety of sources, such as online databases, sensor data, or social media. This involves removing any errors or inconsistencies in the data.
This accessible approach to data transformation ensures that teams can work cohesively on data prep tasks without needing extensive programming skills. With our cleaneddata from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science.
This article was published as a part of the Data Science Blogathon. Introduction A data source can be the original site where data is created or where physical information is first digitized. Still, even the most polished data can be used as a source if it is accessed and used by another process. A data source […].
You’re excited, but there’s a problem – you need data, lots of it, and from various sources. You could spend hours, days, or even weeks scraping websites, cleaningdata, and setting up databases. Or you could use APIs and get all the data you need in a fraction of the time. Well, it’s not.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation.
Therefore, it is important for businesses to take reasonable steps to remove inaccurate, outdated and irrelevant data from their data sets. Data cleansing, or data scrubbing, is the process of analyzing and improving the quality of data stored in a database or other system.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
It detaches from the complicated and computes heavy transformations to deliver cleandata into lakes and DWHs. . Their data pipelining solution moves the business entity data through the concept of micro-DBs, which makes it the first of its kind successful solution.
This article was published as a part of the Data Science Blogathon. Introduction With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time. This outgrows the storage limit and enhances the demand for storing the data across a network of machines.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Companies that use their unstructured data most effectively will gain significant competitive advantages from AI. Cleandata is important for good model performance. Scraped data from the internet often contains a lot of duplications. Access to Amazon OpenSearch as a vector database. read HTML).
The key to this capability lies in the PreciselyID , a unique and persistent identifier for addresses that uses our master location data and address fabric data. We assign a PreciselyID to every address in our database, linking each location to our portfolio’s vast array of data. Easier model maintenance.
Moreover, this feature helps integrate data sets to gain a more comprehensive view or perform complex analyses. DataCleaningData manipulation provides tools to clean and preprocess data. Thus, Cleaningdata ensures data quality and enhances the accuracy of analyses.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
On successful authentication, you will be redirected to the data flow page. Browse to locate loan dataset from the Snowflake database Select the two loans datasets by dragging and dropping them from the left side of the screen to the right. You will be redirected to the Okta login screen to enter Okta credentials to authenticate.
We also reached some incredible milestones with Tableau Prep, our easy-to-use, visual, self-service data prep product. In 2020, we added the ability to write to external databases so you can use cleandata anywhere. Tableau Prep can now be used across more use cases and directly in the browser.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
Dataset The MIMIC Chest X-ray (MIMIC-CXR) Database v2.0.0 We used the MIMIC CXR dataset , which can be accessed through a data use agreement. Context is providing relevant background to ensure the model understands the task or query, such as the schema of a database in the example of natural language querying.
It can be gradually “enriched” so the typical hierarchy of data is thus: Raw data ↓ Cleaneddata ↓ Analysis-ready data ↓ Decision-ready data ↓ Decisions. For example, vector maps of roads of an area coming from different sources is the raw data. Data Intelligence , 2 (1–2), 199–207.
To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database. Imagine, if this is a DCG graph, as shown in the image below, that the cleandata task depends on the extract weather data task.
Data scrubbing is the knight in shining armour for BI. Ensuring cleandata empowers BI tools to generate accurate reports and insights that drive strategic decision-making. Imagine the difference between a blurry picture and a high-resolution image – that’s the power of cleandata in BI.
It’s the critical process of capturing, transforming, and loading data into a centralised repository where it can be processed, analysed, and leveraged. Data Ingestion Meaning At its core, It refers to the act of absorbing data from multiple sources and transporting it to a destination, such as a database, data warehouse, or data lake.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. Sources of DataData can come from multiple sources.
With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. In this blog, we’ll discuss ways to make your data preparation flow run faster. These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables.
With Prep, users can easily and quickly combine, shape, and cleandata for analysis with just a few clicks. In this blog, we’ll discuss ways to make your data preparation flow run faster. These tips can be used in any of your Prep flows but will have the most impact on your flows that connect to large database tables.
R, on the other hand, is renowned for its powerful statistical capabilities, making it ideal for in-depth Data Analysis and modeling. SQL is essential for querying relational databases, which is a common task in Data Analytics. SQL Structured Query Language (SQL) is essential for Data Analysts working with relational databases.
So, let me present to you an Importing Data in Python Cheat Sheet which will make your life easier. For initiating any data science project, first, you need to analyze the data. In this Importing Data in Python Cheat Sheet article, we will explore the essential techniques and libraries that will make data import a breeze.
There are different ways to load data into a data frame, such as from a CSV file, an Excel file, a SQL database, or a web API. data = pd.read_csv('data.csv') CleaningData Once we have loaded the data, we must clean it by removing any missing or duplicated values.
There are 5 stages in unstructured data management: Data collection Data integration DatacleaningData annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. We get your data RAG-ready.
Organisations leverage diverse methods to gather data, including: Direct Data Capture: Real-time collection from sensors, devices, or web services. Database Extraction: Retrieval from structured databases using query languages like SQL. Aggregation: Summarising data into meaningful metrics or aggregates.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. Loading the dataset allows you to begin exploring and manipulating the data.
Customers must acquire large amounts of data and prepare it. This typically involves a lot of manual work cleaningdata, removing duplicates, enriching and transforming it. or “Should I use a relational or non-relational database?”). It’s also not easy to run these models cost-effectively.
It’s essential to ensure that data is not missing critical elements. Consistency Data consistency ensures that data is uniform and coherent across different sources or databases. Timeliness Timeliness relates to the relevance of data at a specific point in time.
This product surfaces rich contextual information via previews, allowing users to interact with data objects within common collaborative applications such as Slack and Tableau. These data objects could include anything from business glossary terms, to a database table or a SQL query with helpful descriptions.
Understand the Data Sources The first step in data standardization is to identify and understand the various data sources that will be standardized. This includes databases, spreadsheets, APIs, and manual records. This could include internal databases, external APIs, and third-party data providers.
By employing ETL, businesses ensure that their data is reliable, accurate, and ready for analysis. This process is essential in environments where data originates from various systems, such as databases , applications, and web services. The key is to ensure that all relevant data is captured for further processing.
This approach can be particularly effective when dealing with real-world applications where data is often noisy or imbalanced. Model-centric AI is well suited for scenarios where you are delivered cleandata that has been perfectly labeled. Consider a customer database that has demographic data for every customer.
This approach can be particularly effective when dealing with real-world applications where data is often noisy or imbalanced. Model-centric AI is well suited for scenarios where you are delivered cleandata that has been perfectly labeled. Consider a customer database that has demographic data for every customer.
For instance, I have experienced machine learning libraries that worked on-premises but not for the cloud version of a database system. In some cases, you might need to keep some data or components on-premises. If it is a static legacy database, this can be a one-time deal. Build Out a Data Synchronization Process.
Data Connectivity: Data Source Compatibility: Power BI can connect to a diverse range of data sources including databases, cloud services, spreadsheets, web services, and more. Direct Query and Import: Users can import data into Power BI or create direct connections to databases for real-time data analysis.
Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. The choice of approach depends on the impact of missing data on the overall dataset and the specific analysis or model being used.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































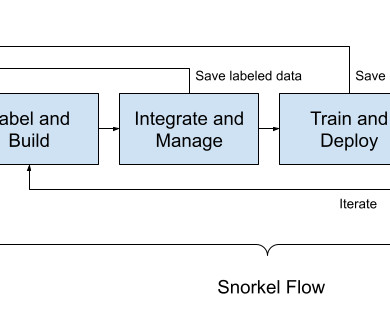
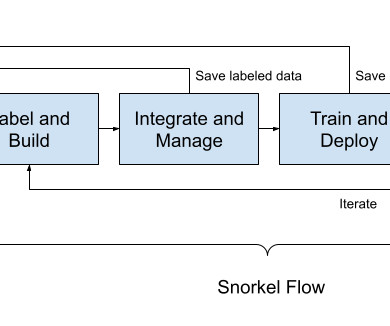









Let's personalize your content