This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will discuss exploratorydataanalysis, also known as EDA, and why it is important. We will also be sharing code snippets so you can try out different analysis techniques yourself. This can be useful for identifying patterns and trends in the data. So, without any further ado let’s dive right in.
Are you curious about what it takes to become a professional data scientist? By following these guides, you can transform yourself into a skilled data scientist and unlock endless career opportunities. Look no further!
Data scientists suffer needlessly when they don’t account for the time it takes to properly complete all of the steps of exploratorydataanalysis There’s a scourge terrorizing data scientists and data science departments across the dataland.
Explore the role and importance of data normalization You might come across certain matches that have missing data on shot outcomes, or any other metric. Correcting these issues ensures your analysis is based on clean, reliable data.
For data scrapping a variety of sources, such as online databases, sensor data, or social media. Cleaningdata: Once the data has been gathered, it needs to be cleaned. This involves removing any errors or inconsistencies in the data.
They employ statistical and mathematical techniques to uncover patterns, trends, and relationships within the data. Data scientists possess a deep understanding of statistical modeling, data visualization, and exploratorydataanalysis to derive actionable insights and drive business decisions.
Its underlying Singer framework allows the data teams to customize the pipeline with ease. It detaches from the complicated and computes heavy transformations to deliver cleandata into lakes and DWHs. . K2View leaps at the traditional approach to ETL and ELT tools.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. DataCleaningDatacleaning is crucial for data integrity.
This crucial step involves handling missing values, correcting errors (addressing Veracity issues from Big Data), transforming data into a usable format, and structuring it for analysis. This often takes up a significant chunk of a data scientist’s time. Think graphs, charts, and summary statistics.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. Loading the dataset allows you to begin exploring and manipulating the data.
Working with inaccurate or poor quality data may result in flawed outcomes. Hence it is essential to review the data and ensure its quality before beginning the analysis process. Ignoring DataCleaningData cleansing is an important step to correct errors and removes duplication of data.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape.
Data scientists must decide on appropriate strategies to handle missing values, such as imputation with mean or median values or removing instances with missing data. The choice of approach depends on the impact of missing data on the overall dataset and the specific analysis or model being used.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
Here are some key areas where Python is particularly useful: Data Mining and CleaningData mining and cleaning are critical steps in any DataAnalysis workflow. For example, handling missing values, formatting data, and normalising data are all simplified through these libraries.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and cleandata, create features, and automate data preparation in ML workflows without writing any code.
In this blog, we’ll be using Python to perform exploratorydataanalysis (EDA) on a Netflix dataset that we’ve found on Kaggle. We’ll be using various Python libraries, including Pandas, Matplotlib, Seaborn, and Plotly, to visualize and analyze the data. The type column tells us if it is a TV show or a movie. df.isnull().sum()
Data engineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together. Using this cleaneddata, our machine learning engineers can develop models to be trained and used to predict metrics such as sales.
It involves handling missing values, correcting errors, removing duplicates, standardizing formats, and structuring data for analysis. ExploratoryDataAnalysis (EDA): Using statistical summaries and initial visualisations (yes, visualisation plays a role within analysis!) EDA: Calculate overall churn rate.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. JG : Exactly.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. JG : Exactly.
While there are a lot of benefits to using data pipelines, they’re not without limitations. Traditional exploratorydataanalysis is difficult to accomplish using pipelines given that the data transformations achieved at each step are overwritten by the proceeding step in the pipeline. JG : Exactly.
Step 3: Data Preprocessing and Exploration Before modeling, it’s essential to preprocess and explore the data thoroughly.This step ensures that you have a clean and well-understood dataset before moving on to modeling. CleaningData: Address any missing values or outliers that could skew results.
Here are some project ideas suitable for students interested in big data analytics with Python: 1. Kaggle datasets) and use Python’s Pandas library to perform datacleaning, data wrangling, and exploratorydataanalysis (EDA).
Datacleaning identifies and addresses these issues to ensure data quality and integrity. DataAnalysis: This step involves applying statistical and Machine Learning techniques to analyse the cleaneddata and uncover patterns, trends, and relationships.
Finding the Best CEFR Dictionary This is one of the toughest parts of creating my own machine learning program because cleandata is one of the most important parts. ExploratoryDataAnalysis This is one of the fun parts because we get to look into and analyze what’s inside the data that we have collected and cleaned.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model.
It is important to experience such problems as they reflect a lot of the issues that a data practitioner is bound to experience in a business environment. We first get a snapshot of our data by visually inspecting it and also performing minimal ExploratoryDataAnalysis just to make this article easier to follow through.
Roles and responsibilities of a data scientist Data scientists are tasked with several important responsibilities that contribute significantly to data strategy and decision-making within an organization. Analyzing data trends: Using analytic tools to identify significant patterns and insights for business improvement.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

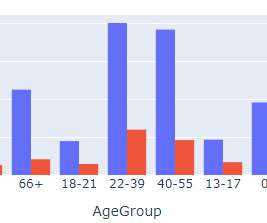




































Let's personalize your content