This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will discuss exploratorydataanalysis, also known as EDA, and why it is important. We will also be sharing code snippets so you can try out different analysis techniques yourself. This can be useful for identifying patterns and trends in the data. So, without any further ado let’s dive right in.
Are you curious about what it takes to become a professional data scientist? By following these guides, you can transform yourself into a skilled data scientist and unlock endless career opportunities. Look no further!
They employ statistical and mathematical techniques to uncover patterns, trends, and relationships within the data. Data scientists possess a deep understanding of statistical modeling, data visualization, and exploratorydataanalysis to derive actionable insights and drive business decisions.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in DataAnalysis. It excels in datacleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights. In this blog, we’ll be using Python to perform exploratorydataanalysis (EDA) on a Netflix dataset that we’ve found on Kaggle. The type column tells us if it is a TV show or a movie. df.isnull().sum()
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and cleandata from multiple sources, ensuring it is suitable for analysis. Automated systems can extract data from websites or applications.
” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape. Interprets data to uncover actionable insights guiding business decisions.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
These may range from Data Analytics projects for beginners to experienced ones. Following is a guide that can help you understand the types of projects and the projects involved with Python and Business Analytics. Here are some project ideas suitable for students interested in big data analytics with Python: 1.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
Jason Goldfarb, senior data scientist at State Farm , gave a presentation entitled “Reusable DataCleaning Pipelines in Python” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. It has always amazed me how much time the datacleaning portion of my job takes to complete.
It involves handling missing values, correcting errors, removing duplicates, standardizing formats, and structuring data for analysis. ExploratoryDataAnalysis (EDA): Using statistical summaries and initial visualisations (yes, visualisation plays a role within analysis!) EDA: Calculate overall churn rate.
Finding the Best CEFR Dictionary This is one of the toughest parts of creating my own machine learning program because cleandata is one of the most important parts. But I have to say that this data is of great quality because we already converted it from messy data into the Python dictionary format that matches our type of work.
Datacleaning identifies and addresses these issues to ensure data quality and integrity. DataAnalysis: This step involves applying statistical and Machine Learning techniques to analyse the cleaneddata and uncover patterns, trends, and relationships.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
To borrow another example from Andrew Ng, improving the quality of data can have a tremendous impact on model performance. This is to say that cleandata can better teach our models. Another benefit of clean, informative data is that we may also be able to achieve equivalent model performance with much less data.
This step involves several tasks, including datacleaning, feature selection, feature engineering, and data normalization. It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model.
A Python 3.9+ The following python libraries: comet_ml, Scikit-learn, and Pandas. Project The dataset for my project will be one that might require substantial changes through datacleaning as most real-world datasets would require. They are: A Comet ML account. You can get one here. installation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

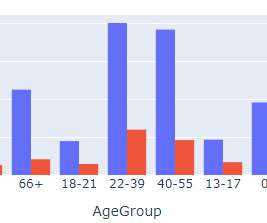


























Let's personalize your content