This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor data quality can lead to inaccurate predictions and poor model performance.
Data scientists are also some of the highest-paid job roles, so data scientists need to quickly show their value by getting to real results as quickly, safely, and accurately as possible. Data Scientists of Varying Skillsets Learn AI – ML Through Technical Blogs. Read the blog. See DataRobot in Action.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler.
Data preprocessing and feature engineering: They are responsible for preparing and cleaningdata, performing feature extraction and selection, and transforming data into a format suitable for model training and evaluation.
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Everybody knows you need to clean your data to get good ML performance. How does cleanlab work?
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms. Cleaningdata: Once the data has been gathered, it needs to be cleaned.
This accessible approach to data transformation ensures that teams can work cohesively on data prep tasks without needing extensive programming skills. With our cleaneddata from step one, we can now join our vehicle sensor measurements with warranty claim data to explore any correlations using data science.
The Set Up If ChatGPT is to function as an ML engineer, it is best to run an inventory of the tasks that the role entails. The daily life of an ML engineer includes among others: Manual inspection and exploration of data Training models and evaluating model results Managing model deployments and model monitoring processes.
In the dynamic world of sports analytics, machine learning (ML) systems play a pivotal role, transforming vast arrays of visual data into actionable insights. Yet, not all sports environments cater equally to the capabilities of current ML models. Figure 4: Rank@1 accuracy and mean average precision (mAP) on the MUDD dataset.
AI in marketing refers to the use of machine learning (ML), natural language processing (NLP), and predictive analytics to automate, optimize, and personalize campaigns at scale. Pro Tip “Treat AI like a new hiretrain it with cleandata, document its decisions, and supervise its work.” Lets dive right in.
In the dynamic world of sports analytics, machine learning (ML) systems play a pivotal role, transforming vast arrays of visual data into actionable insights. Yet, not all sports environments cater equally to the capabilities of current ML models. Figure 4: Rank@1 accuracy and mean average precision (mAP) on the MUDD dataset.
Key Takeaways: Data enrichment is the process of appending your internal data with relevant context from additional sources – enhancing your data’s quality and value. Data enrichment improves your AI/ML outcomes: boosting accuracy, performance, and utility across all applications throughout your business.
I’ve passed many ML courses before, so that I can compare. You start with the working ML model. Lesson #2: How to clean your data We are used to starting analysis with cleaningdata. Surprisingly, fitting a model first and then using it to clean your data may be more effective.
ML teams have a very important core purpose in their organizations - delivering high-quality, reliable models, fast. With users’ productivity in mind, at DagHub we aimed for a solution that will provide ML teams with the whole process out of the box and with no extra effort.
This includes datacleaning, data normalization, and feature selection. Suboptimal values can result in poor performance or overfitting, while optimal values can lead to better generalization and improved accuracy. In summary, hyperparameter tuning is crucial to maximizing the performance of a model.
Raw data often contains inconsistencies, missing values, and irrelevant features that can adversely affect the performance of Machine Learning models. Proper preprocessing helps in: Improving Model Accuracy: Cleandata leads to better predictions. The post ML | Data Preprocessing in Python appeared first on Pickl.AI.
How to Scale Your Data Quality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
With advanced analytics derived from machine learning (ML), the NFL is creating new ways to quantify football, and to provide fans with the tools needed to increase their knowledge of the games within the game of football. Next, we present the data preprocessing and other transformation methods applied to the dataset.
In this first post, we introduce mobility data, its sources, and a typical schema of this data. We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights.
Evaluating LLMs is an undervalued part of the machine learning (ML) pipeline. This dataset was uploaded to Amazon Simple Service (Amazon S3) data source and then ingested using Knowledge Bases for Amazon Bedrock. She has extensive experience in the application of AI/ML within the healthcare domain, especially in radiology.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and cleandata, create features, and automate data preparation in machine learning (ML) workflows without writing any code.
In this article, we will discuss how Python runs data preprocessing with its exhaustive machine learning libraries and influences business decision-making. Data Preprocessing is a Requirement. Data preprocessing is converting raw data to cleandata to make it accessible for future use.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Data scientist experience In this section, we cover how data scientists can connect to Snowflake as a data source in Data Wrangler and prepare data for ML.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. A transcript of the talk follows.
He presented “Building Machine Learning Systems for the Era of Data-Centric AI” at Snorkel AI’s The Future of Data-Centric AI event in 2022. The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. A transcript of the talk follows.
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
Wayfair relies on machine learning (ML) and product tagging to ensure customer searches result in relevant products. With over 10,000 product tags across 40 million products, creating and managing labeled data is an enormous and time-consuming effort. Rich information was buried within images and was challenging to extract and utilize.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. He obtained his Ph.D.
ArticleVideo Book This article was published as a part of the Data Science Blogathon AGENDA: Introduction Machine Learning pipeline Problems with data Why do we. The post 4 Ways to Handle Insufficient Data In Machine Learning! appeared first on Analytics Vidhya.
Companies that use their unstructured data most effectively will gain significant competitive advantages from AI. Cleandata is important for good model performance. Scraped data from the internet often contains a lot of duplications. Extracted texts still have large amounts of gibberish and boilerplate text (e.g.,
Additionally, Tableau allows customers using BigQuery ML to easily visualize the results of predictive machine learning models run on data stored in BigQuery. Our customers also need a way to easily clean, organize and distribute this data. Operationalizing Tableau Prep flows to BigQuery.
Wayfair relies on machine learning (ML) and product tagging to ensure customer searches result in relevant products. With over 10,000 product tags across 40 million products, creating and managing labeled data is an enormous and time-consuming effort. Rich information was buried within images and was challenging to extract and utilize.
AWS innovates to offer the most advanced infrastructure for ML. For ML specifically, we started with AWS Inferentia, our purpose-built inference chip. Neuron plugs into popular ML frameworks like PyTorch and TensorFlow, and support for JAX is coming early next year. Customers like Adobe, Deutsche Telekom, and Leonardo.ai
Don’t think you have to manually do all of the data curation work yourself! New algorithms/software can help you systematically curate your data via automation. In this post, I’ll give a high-level overview of how AI/ML can be used to automatically detect various issues common in real-world datasets.
Data scrubbing is the knight in shining armour for BI. Ensuring cleandata empowers BI tools to generate accurate reports and insights that drive strategic decision-making. Imagine the difference between a blurry picture and a high-resolution image – that’s the power of cleandata in BI.
Sheer volume of data makes automation with Artificial Intelligence & Machine Learning (AI & ML) an imperative. Menninger outlines how modern data governance practices may deploy a basic repository of data; this can help with some level of automation. Access the Ventana report, Diving Deeper Into the Data Lake.
The quality of your training data in Machine Learning (ML) can make or break your entire project. Iterative Training : Models should be retrained and fine-tuned with new data to keep up with evolving scenarios, especially in fields like healthcare, finance, and autonomous driving.
On the client side, Snowpark consists of libraries, including the DataFrame API and native Snowpark machine learning (ML) APIs for model development (public preview) and deployment (private preview). Machine Learning Training machine learning (ML) models can sometimes be resource-intensive.
Additionally, Tableau allows customers using BigQuery ML to easily visualize the results of predictive machine learning models run on data stored in BigQuery. Our customers also need a way to easily clean, organize and distribute this data. Operationalizing Tableau Prep flows to BigQuery.
At its core, NLP in machine learning (ML) is where the intricate art of language meets the precision of algorithms. It’s akin to teaching machines to not merely recognize words but to respond to them in ways that mimic human understanding, forging connections that transcend mere data processing.
We asked the community to bring its best and most recent research on how to further the field of data-centric AI, and our accepted applicants have delivered. Those approved so far cover a broad range of themes—including datacleaning, data labeling, and data integration.
We asked the community to bring its best and most recent research on how to further the field of data-centric AI, and our accepted applicants have delivered. Those approved so far cover a broad range of themes—including datacleaning, data labeling, and data integration.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


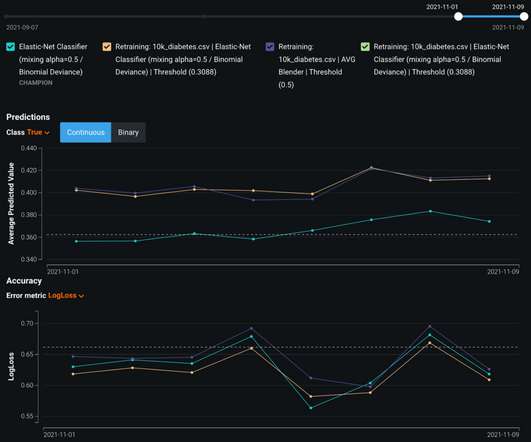














































Let's personalize your content