This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Data Cleansing is the process of analyzing data for finding. The post Data Cleansing: How To CleanData With Python! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Python is an easy-to-learn programming language, which makes it the. The post How to cleandata in Python for Machine Learning? appeared first on Analytics Vidhya.
Are you curious about what it takes to become a professional data scientist? By following these guides, you can transform yourself into a skilled data scientist and unlock endless career opportunities. Look no further!
Automating datacleaning can speed up […] The post 5-Step Guide to Automate DataCleaning in Python appeared first on Analytics Vidhya. However, this takes up a lot of time, even for experts, as most of the process is manual.
Introduction In this article, we will be getting our hands dirty with PySpark using Python and understand how to get started with data preprocessing using PySpark. This particular article’s whole attention is to get to know how PySpark can help in the datacleaning process […].
Overview Regular Expressions or Regex is a versatile tool that every Data Scientist should know about Regex can automate various mundane data processing tasks. The post 4 Applications of Regular Expressions that every Data Scientist should know (with Python code)! appeared first on Analytics Vidhya.
Introduction Python is a versatile and powerful programming language that plays a central role in the toolkit of data scientists and analysts. Its simplicity and readability make it a preferred choice for working with data, from the most fundamental tasks to cutting-edge artificial intelligence and machine learning.
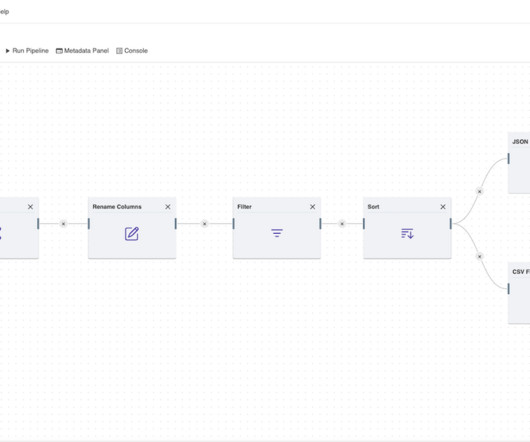
Amphi is a micro ETL designed for extracting, preparing and cleaningdata from various sources and formats. Develop data pipelines and generate native Python code you can deploy anywhere.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Datacleaning and Data Manipulation is one. The post DataCleaning Libraries In Python: A Gentle Introduction appeared first on Analytics Vidhya. Introduction Welcome Readers!!
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Interpolation is a technique in Python used to estimate unknown. The post Interpolation – Power of Interpolation in Python to fill Missing Values appeared first on Analytics Vidhya.
Still, data scientists and their daily task are to clean the data so that machine learning algorithms will have the data good enough to […]. The post Template for DataCleaning using Python appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Image 1In this blog, We are going to talk about some of the advanced and most used charts in Plotly while doing analysis. Table of content Description of Dataset Data Exploration DataCleaningData visualization […].
This article was published as a part of the Data Science Blogathon Introduction Do you wish you could perform this function using Pandas. For data scientists who use Python as their primary programming language, the Pandas package is a must-have data analysis tool. Well, there is a good possibility you can!
That’s because the machine learning projects go through and process a lot of data, and that data should come in the specified format to make it easier for the AI to catch and process. Likewise, Python is a popular name in the data preprocessing world because of its ability to process the functionalities in different ways.
Excel is getting a bump in capabilities with Python integration. From Microsoft : Excel users now have access to powerful analytics via Python for visualizations, cleaningdata, machine learning, predictive analytics, and more. Sounds fun for both Excel users and Python developers. Tags: Excel , Python
Descriptive statistics Grouping and aggregating: One way to explore a dataset is by grouping the data by one or more variables, and then aggregating the data by calculating summary statistics. This can be useful for identifying patterns and trends in the data.
Pandas is one of the most prominent Python Packages for data exploration and manipulation. Every data professional learning Python would come across Pandas during their work. That's why we would learn about the Python package that embeds LLM with Pandas — PandasAI.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in Data Analysis. It excels in datacleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists. Why Python?
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality.
Summary: This article discusses the interoperability of Python, MATLAB, and R, emphasising their unique strengths in Data Science, Engineering, and Statistical Analysis. It highlights the importance of combining these languages for efficient workflows while addressing challenges such as data compatibility and performance bottlenecks.
Raw data is processed to make it easier to analyze and interpret. Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. This blog article will look at manipulating data using Python and Jupyter Notebooks.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Data- a world-changing gamer is a key component for all. The post Let’s Understand All About Data Wrangling! appeared first on Analytics Vidhya.
” – Zig Zagler As data scientists, we are often taught to be. The post 10 Awesome Data Manipulation and Wrangling Hacks, Tips and Tricks appeared first on Analytics Vidhya. Introduction “Efficiency is doing things right. Effectiveness is doing the right thing.”
In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights. In this blog, we’ll be using Python to perform exploratory data analysis (EDA) on a Netflix dataset that we’ve found on Kaggle. Let’s explore the dataset further by cleaningdata and creating some visualizations.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor data quality can lead to inaccurate predictions and poor model performance.
ArticleVideos This article was published as a part of the Data Science Blogathon. Introduction The concept of cleaning and cleansing spiritually, and hygienically are. The post The Importance of Cleaning and Cleansing your Data appeared first on Analytics Vidhya.
This leads to predictable results – according to Statista, the amount of data generated globally is expected to surpass 180 zettabytes in 2025. On the one hand, having many resources to make […] The post How to Work with Unstructured Data in Python appeared first on DATAVERSITY.
This article was published as a part of the Data Science Blogathon. Introduction A business or a brand’s success depends solely on customer satisfaction. Suppose, if the customer does not like the product, you may have to work on the product to make it more efficient. So, for you to identify this, you will be […].
This article was published as a part of the Data Science Blogathon Introduction You must be aware of the fact that Feature Engineering is the heart of any Machine Learning model. How successful a model is or how accurately it predicts that depends on the application of various feature engineering techniques. In this article, we are […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Data Preprocessing Data preprocessing is the process of transforming raw data. The post Data Preprocessing in Data Mining -A Hands On Guide appeared first on Analytics Vidhya.
You’re excited, but there’s a problem – you need data, lots of it, and from various sources. You could spend hours, days, or even weeks scraping websites, cleaningdata, and setting up databases. Or you could use APIs and get all the data you need in a fraction of the time. Sounds like a dream, right?
This article was published as a part of the Data Science Blogathon Why should we use Feature Engineering? Feature Engineering is one of the beautiful arts which helps you to represent data in the most insightful possible way. It entails a skilled combination of subject knowledge, intuition, and fundamental mathematical skills.
This article was published as a part of the Data Science Blogathon. Introduction Web scraping, is an approach to extract content and data from a website. There are ample ways to get data from websites. […]. The post Multiple Web Scraping Using Beautiful Soap Library appeared first on Analytics Vidhya.
If you do not take your time to clean up this list, then there is every […] The post What is Data Scrubbing? Introduction Think of the fact that you’re planning a massive family gathering. You have a list of attendees, but it is full of wrong contacts, the same contacts and some of the names in the list are spelled wrongly.
This article was published as a part of the Data Science Blogathon. Introduction As a Machine Learning Engineer or Data Engineer, your main task is to identify and clean duplicate data and remove errors from the dataset. The post A Complete Guide to Pyjanitor for DataCleaning appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction “Data is the fuel for Machine Learning algorithms” Real-world. The post How to Handle Missing Values of Categorical Variables? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pandas Pandas is an open-source data analysis and data manipulation library. The post Data Manipulation Using Pandas | Essential Functionalities of Pandas you need to know! appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time. This outgrows the storage limit and enhances the demand for storing the data across a network of machines.
Companies that use their unstructured data most effectively will gain significant competitive advantages from AI. Cleandata is important for good model performance. Scraped data from the internet often contains a lot of duplications. Choose Python (PySpark) for this use-case. And select Python (PySpark).
ArticleVideo Book This article was published as a part of the Data Science Blogathon AGENDA: Introduction Machine Learning pipeline Problems with data Why do we. The post 4 Ways to Handle Insufficient Data In Machine Learning! appeared first on Analytics Vidhya.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building data pipelines.
The extraction of raw data, transforming to a suitable format for business needs, and loading into a data warehouse. Data transformation. This process helps to transform raw data into cleandata that can be analysed and aggregated. Data analytics and visualisation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content