This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A DataWarehouse is Built by combining data from multiple. The post A Brief Introduction to the Concept of DataWarehouse appeared first on Analytics Vidhya.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures?
Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming data pipeline to power such dashboards may […] The post DataEngineering for Streaming Data on GCP appeared first on Analytics Vidhya.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Amazon Redshift is a datawarehouse service in the cloud. The post Understand All About Amazon Redshift! appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. It involves extracting the operational data from various sources, transforming it into a format suitable for business needs, and loading it into data storage systems.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. What is The Cloud?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Businesses increasingly rely on up-to-the-moment information to respond swiftly to market shifts and consumer behaviors Unstructured data challenges : The surge in unstructured data—videos, images, social media interactions—poses a significant challenge to traditional ETL tools.
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […].
Introduction Publish and Subscribe is a messaging mechanism having one or a set of senders sending messages and one or a group of receivers receiving these messages.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
This article was published as a part of the Data Science Blogathon. Introduction Data sharing has become so easy today, and we can share the details with just a few clicks. The post How to Encrypt and Decrypt the Data in PySpark? These details can get leaked if the […].
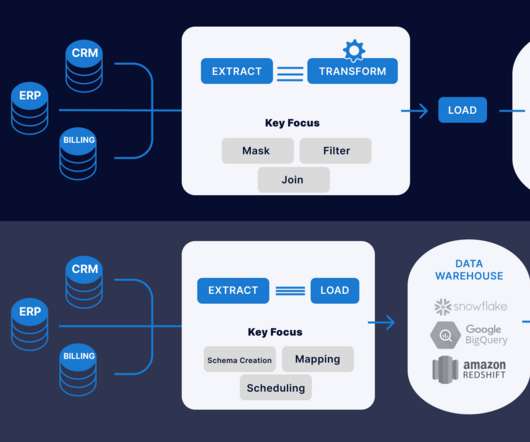
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency.
Today, OLAP database systems have become comprehensive and integrated data analytics platforms, addressing the diverse needs of modern businesses. They are seamlessly integrated with cloud-based datawarehouses, facilitating the collection, storage and analysis of data from various sources.
Introduction A data lake is a centralized and scalable repository storing structured and unstructured data. The need for a data lake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
By leveraging Azure’s capabilities, you can gain the skills and experience needed to excel in this dynamic field and contribute to cutting-edge data solutions. Microsoft Azure, often referred to as Azure, is a robust cloudcomputing platform developed by Microsoft. What is Azure?
Snowflake is a cloudcomputing–based datacloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. On the other hand, Snowflake wants to drive as much storage and compute onto their platform as possible too.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content