This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
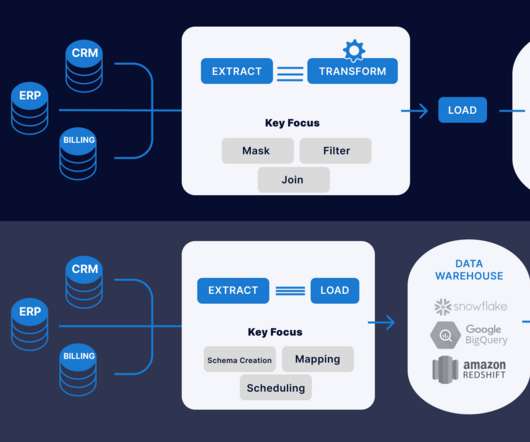
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
In the contemporary age of Big Data, Data Warehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures? appeared first on Data Science Blog.
Best tools and platforms for MLOPs – Data Science Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloudcomputing services. It offers a range of products, including Google Cloud Storage, Google Cloud Deployment Manager, Google Cloud Functions, and others.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
When accepting the investment character of big data extractions, the investment should be done properly in the beginning and therefore cost beneficial in the long term. Cloud-Based infrastructure with process mining? Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
DataEngineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. CloudComputing : Utilizing cloud services for data storage and processing, often covering platforms such as AWS, Azure, and Google Cloud.
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern data warehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization.
Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? A Note on the Shift from ETL to ELT.
This method not only expands the available training data but also enhances model efficiency and problem-solving abilities. Ive been a DataEngineering guy for the last decade, so my solution for bad data is immediately a technical solution like below more cleaning scripts, better validation rules, improved monitoring dashboards.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. First of all, the origin of the data comes from the two biggest exchanges.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content