This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Introduction Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines.
What businesses need from cloudcomputing is the power to work on their data without having to transport it around between different clouds, different databases and different repositories, different integrations to third-party applications, different datapipelines and different compute engines.
Summary: “Data Science in a Cloud World” highlights how cloudcomputing transforms Data Science by providing scalable, cost-effective solutions for big data, Machine Learning, and real-time analytics. Advancements in data processing, storage, and analysis technologies power this transformation.
Observo AI, an artificial intelligence-powered datapipeline company that helps companies solve observability and security issues, said Thursday it has raised $15 million in seed funding led by Felici
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Best tools and platforms for MLOPs – Data Science Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloudcomputing services. It offers a range of products, including Google Cloud Storage, Google Cloud Deployment Manager, Google Cloud Functions, and others.
Automation Automating datapipelines and models ➡️ 6. The Data Engineer Not everyone working on a data science project is a data scientist. Data engineers are the glue that binds the products of data scientists into a coherent and robust datapipeline.
Businesses increasingly rely on up-to-the-moment information to respond swiftly to market shifts and consumer behaviors Unstructured data challenges : The surge in unstructured data—videos, images, social media interactions—poses a significant challenge to traditional ETL tools.
Computer science, math, statistics, programming, and software development are all skills required in NLP projects. CloudComputing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops.
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
As a Technical Architect at Precisely, I’ve had the unique opportunity to lead the AWS Mainframe Modernization Data Replication for IBM i initiative, a project that not only challenged our technical capabilities but also enriched our understanding of cloud integration complexities.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Over the past few years, enterprise data architectures have evolved significantly to accommodate the changing data requirements of modern businesses. Data warehouses were first introduced in the […] The post Are Data Warehouses Still Relevant?
Yet mainframes weren’t designed to integrate easily with modern distributed computing platforms. Cloudcomputing, object-oriented programming, open source software, and microservices came about long after mainframes had established themselves as a mature and highly dependable platform for business applications.
This involves creating data validation rules, monitoring data quality, and implementing processes to correct any errors that are identified. Creating datapipelines and workflows Data engineers create datapipelines and workflows that enable data to be collected, processed, and analyzed efficiently.
But keep in mind one thing which is you have to either replicate the topics in your cloud cluster or you will have to develop a custom connector to read and copy back and forth from the cloud to the application. 5 Key Comparisons in Different Apache Kafka Architectures.
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern data warehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. CloudComputing : Utilizing cloud services for data storage and processing, often covering platforms such as AWS, Azure, and Google Cloud.
Serverless, or serverless computing, is an approach to software development that empowers developers to build and run application code without having to worry about maintenance tasks like installing software updates, security, monitoring and more. Despite its name, a serverless framework doesn’t mean computing without servers.
Monte Carlo Monte Carlo is a popular data observability platform that provides real-time monitoring and alerting for data quality issues. It could help you detect and prevent datapipeline failures, data drift, and anomalies. Metaplane supports collaboration, anomaly detection, and data quality rule management.
Scalable and flexible infrastructure — Processing big data requires an infrastructure that adapts to rapidly growing processing needs and different scenarios of data storage and usage. This entails the use of other technologies such as distributed computing, edge computing, and cloudcomputing.
Failing to make production data accessible in the cloud. Data professionals often enable many different cloud-native services to help users perform distributed computations, build and store container images, create datapipelines, and more.
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
That creates new challenges in data management and analytics. Each new system comes with its own schema, which must be mapped and normalized alongside other data. The best integration tools make it easy to build and deploy datapipelines to accommodate the ever-changing needs of modern financial services organizations.
Yet mainframes weren’t initially designed to integrate easily with modern distributed computing platforms. Cloudcomputing, object-oriented programming, open source software, and microservices came about long after mainframes had established themselves as a mature and highly dependable platform for business applications.
According to the IDC report, “organizations that have implemented DataOps have seen a 40% reduction in the number of data and application exceptions or errors and a 49% improvement in the ability to deliver data projects on time.”
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloudcomputing and clouddata warehousing has catalyzed the growth of the modern data stack.
When the data or pipeline configuration needs to be changed, tools like Fivetran and dbt reduce the time required to make the change, and increase the confidence your team can have around the change. These allow you to scale your pipelines quickly. Governance When talking about scaling, governance doesn’t often come up.
Security is Paramount Implement robust security measures to protect sensitive time series data. Integration with DataPipelines and Analytics TSDBs often work in tandem with other data tools to create a comprehensive data ecosystem for analysis and insights generation.
A cloud-ready data discovery process can ease your transition to cloudcomputing and streamline processes upon arrival. So how do you take full advantage of the cloud? Migration leaders would be wise to enable all the enhancements a cloud environment offers, including: Special requirements for AI/ML.
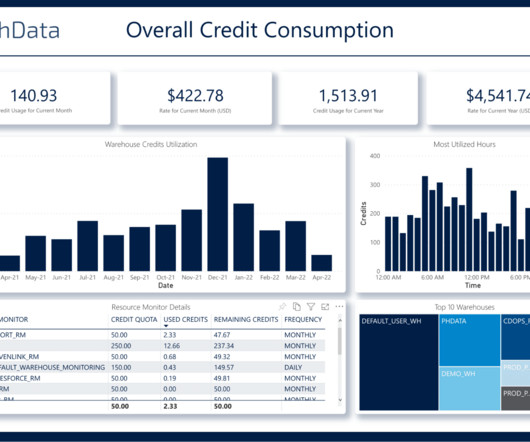
Snowflake is a cloudcomputing–based datacloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. Table of Contents Why Discuss Snowflake & Power BI?
Understanding the Cost of Snowflake Like any other cloudcomputing tool, costs can quickly add up if not kept in check. The total cost of using Snowflake is the aggregate of the cost of using data transfer, storage, and computing resources.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. The CI/CD was crucial for preventing accidents such as unwanted pipeline executions, and we implemented the use of GitHub Actions to trigger some tasks , such as the datapipeline deployment.
PCI-DSS (Payment Card Industry Data Security Standard): Ensuring your credit card information is securely managed. HITRUST: Meeting stringent standards for safeguarding healthcare data. CSA STAR Level 1 (Cloud Security Alliance): Following best practices for security assurance in cloudcomputing.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
By leveraging Azure’s capabilities, you can gain the skills and experience needed to excel in this dynamic field and contribute to cutting-edge data solutions. Microsoft Azure, often referred to as Azure, is a robust cloudcomputing platform developed by Microsoft. What is Azure?
But the most impactful developments may be those focused on governance, middleware, training techniques and datapipelines that make generative AI more trustworthy , sustainable and accessible, for enterprises and end users alike. Here are some important current AI trends to look out for in the coming year.
All data generation and processing steps were run in parallel directly on the SageMaker HyperPod cluster nodes, using a unique working environment and highlighting the clusters versatility for various tasks beyond just training models. In his free time, Giuseppe enjoys playing football.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content