This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What businesses need from cloudcomputing is the power to work on their data without having to transport it around between different clouds, different databases and different repositories, different integrations to third-party applications, different datapipelines and different compute engines.
Summary: “Data Science in a Cloud World” highlights how cloudcomputing transforms Data Science by providing scalable, cost-effective solutions for big data, Machine Learning, and real-time analytics. Advancements in data processing, storage, and analysis technologies power this transformation.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
Automation Automating datapipelines and models ➡️ 6. The Data Engineer Not everyone working on a data science project is a data scientist. Data engineers are the glue that binds the products of data scientists into a coherent and robust datapipeline.
As a Technical Architect at Precisely, I’ve had the unique opportunity to lead the AWS Mainframe Modernization Data Replication for IBM i initiative, a project that not only challenged our technical capabilities but also enriched our understanding of cloud integration complexities.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. This section explores essential aspects of Data Engineering.
Yet mainframes weren’t designed to integrate easily with modern distributed computing platforms. Cloudcomputing, object-oriented programming, open source software, and microservices came about long after mainframes had established themselves as a mature and highly dependable platform for business applications.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
That creates new challenges in data management and analytics. Each new system comes with its own schema, which must be mapped and normalized alongside other data. The best integration tools make it easy to build and deploy datapipelines to accommodate the ever-changing needs of modern financial services organizations.
When the data or pipeline configuration needs to be changed, tools like Fivetran and dbt reduce the time required to make the change, and increase the confidence your team can have around the change. These allow you to scale your pipelines quickly. Governance When talking about scaling, governance doesn’t often come up.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloudcomputing and clouddata warehousing has catalyzed the growth of the modern data stack.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
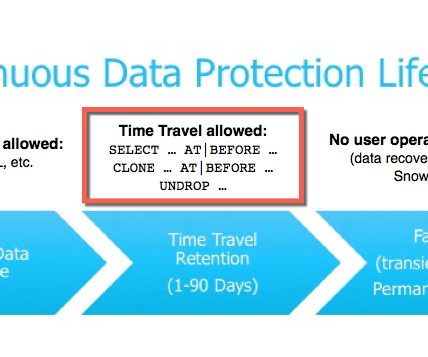
Access Controls and User Authentication Access control regulates who can interact with various database objects, such as tables, views, and functions. In Snowflake, securable objects (representing database resources) are controlled through roles. HITRUST: Meeting stringent standards for safeguarding healthcare data.
A cloud-ready data discovery process can ease your transition to cloudcomputing and streamline processes upon arrival. So how do you take full advantage of the cloud? Migration leaders would be wise to enable all the enhancements a cloud environment offers, including: Special requirements for AI/ML.
Snowflake is a cloudcomputing–based datacloud company that provides data warehousing services that are far more scalable and flexible than traditional data warehousing products. Importing data allows you to ingest a copy of the source data into an in-memory database.
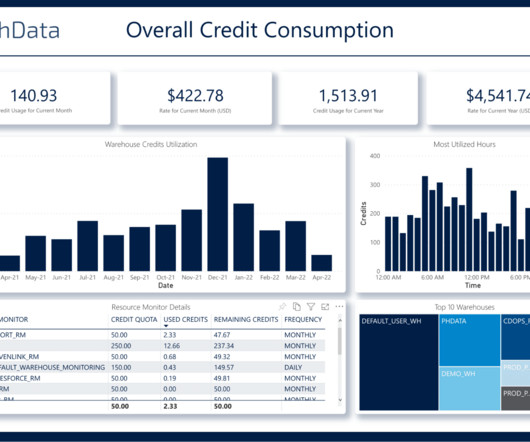
Understanding the Cost of Snowflake Like any other cloudcomputing tool, costs can quickly add up if not kept in check. The total cost of using Snowflake is the aggregate of the cost of using data transfer, storage, and computing resources.
By leveraging Azure’s capabilities, you can gain the skills and experience needed to excel in this dynamic field and contribute to cutting-edge data solutions. Microsoft Azure, often referred to as Azure, is a robust cloudcomputing platform developed by Microsoft. What is Azure?
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
The deduplication process involved embedding dataset elements using a text embedder, then computing cosine similarity between the embeddings to identify similar elements. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services.
But the most impactful developments may be those focused on governance, middleware, training techniques and datapipelines that make generative AI more trustworthy , sustainable and accessible, for enterprises and end users alike. Here are some important current AI trends to look out for in the coming year.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content