This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration.
Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
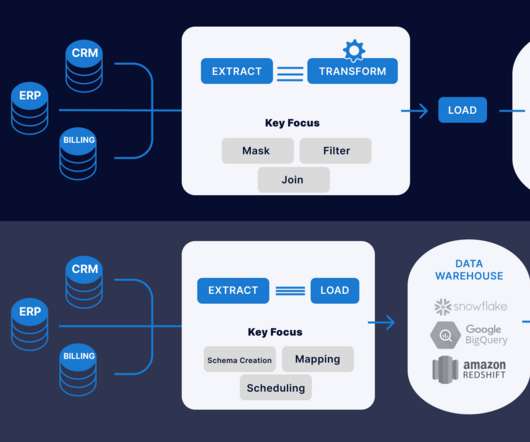
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. However, the exponential growth in data volume, velocity, and variety is challenging the traditional paradigms of ETL, ushering in a transformative era.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. This article was published as a part of the Data Science Blogathon. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. This blog explores the fundamental concepts of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), two pivotal methods in modern data architectures. What is ETL?
With the evolution of cloudcomputing, many organizations are now migrating their Data Warehouse Systems to the cloud for better scalability, flexibility, and cost-efficiency. So why using IaC for Cloud Data Infrastructures? Infrastructure as Code (IaC) can be a game-changer in this scenario.
But keep in mind one thing which is you have to either replicate the topics in your cloud cluster or you will have to develop a custom connector to read and copy back and forth from the cloud to the application. A three-step ETL framework job should do the trick. Step 3: Create an ETL job and save that data to a data lake.
Best tools and platforms for MLOPs – Data Science Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloudcomputing services. It offers a range of products, including Google Cloud Storage, Google Cloud Deployment Manager, Google Cloud Functions, and others.
The popular tools, on the other hand, include Power BI, ETL, IBM Db2, and Teradata. CloudComputing and Related Mechanics. Big data, advanced analytics, machine learning, none of these technologies would exist without cloudcomputing and the resulting infrastructure.
Cloud-Based infrastructure with process mining? Depending on the data strategy of one organization, one cost-effective approach to process mining could be to leverage cloudcomputing resources. But costs won’t decrease only migrating from on-premises to cloud and vice versa.
Reverse ETL tools. The rise of cloudcomputing and cloud data warehousing has catalyzed the growth of the modern data stack. The rise of cloudcomputing and cloud data warehousing has catalyzed the growth of the modern data stack. A Note on the Shift from ETL to ELT. Data orchestration tools.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. They are skilled at deploying to any cloud or on-premises infrastructure. Data engineers are the glue that binds the products of data scientists into a coherent and robust data pipeline.
In this post, we will be particularly interested in the impact that cloudcomputing left on the modern data warehouse. In the cloud, the physical distance between the data source and the cloud data warehouse region can impact latency. Data integrations and pipelines can also impact latency.
Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. CloudComputing : Utilizing cloud services for data storage and processing, often covering platforms such as AWS, Azure, and Google Cloud.
This entails the use of other technologies such as distributed computing, edge computing, and cloudcomputing. When it comes to data integration, RTOS can work with systems that employ data warehousing, API management, and ETL technologies. Moreover, RTOS is built to be scalable and flexible.
These tools enable the extraction, transformation, and loading (ETL) of data from various sources. Cloud-based solutions Cloudcomputing offers scalability, flexibility, and accessibility, making it an ideal choice for integrated business planning.
As cloudcomputing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
This involves working with various tools and technologies, such as ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, to move data from its source to its destination. Cloudcomputing: Cloudcomputing provides a scalable and cost-effective solution for managing and processing large volumes of data.
Twenty years ago, top-performing organizations were using “extract, transform, load” (ETL) processes to normalize and aggregate data for business analytics. Cloudcomputing technology improves the speed and scale at which organizations can process data. Real-time data is the goal.
Answer : Microsoft Azure is a cloudcomputing platform and service that Microsoft provides. This includes Database System Management (SQL or Non-SQL), Data Warehousing, Machine Learning, programming basics, and ETL. Following the potential questions in general that you might get asked: 1. What is Microsoft Azure?
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. These tools help organisations harness the power of cloudcomputing for Data Engineering solutions.
With the rise of cloudcomputing, the MDS has evolved even further to include cloud-based storage and tools for analysis. Having a singular ELT/ETL solution is a firm requirement Dbt does not handle ingestion well, it works best when paired with another ingestion tool such as Fivetran.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach.
Consider these common scenarios: A perfect validation script cant fix inconsistent data entry practices The most robust ETL pipeline cant resolve disagreements about business rules Real-time quality monitoring cant replace clear data ownership.
In this post, we demonstrate how to use Amazon OpenSearch Service with purpose-built document ETL tools, Aryn DocParse and Sycamore, to quickly build a RAG application that relies on complex documents. We use over 75 PDF reports from the National Transportation Safety Board (NTSB) about aircraft incidents.
His work is focused on the implementation of efficient ETL data analytics pipelines, and solving business problems via automation, experimenting and innovating using AWS services with a code-first approach using AWS CDK. Martin Gregory is a Senior Market Data Technician at Parameta Solutions with over 25 years of experience.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content