This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction We are all pretty much familiar with the common modern clouddata warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a data warehouse compute engine […].
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Create Lakehouse: Now, let’s create a lakehouse to store the data.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
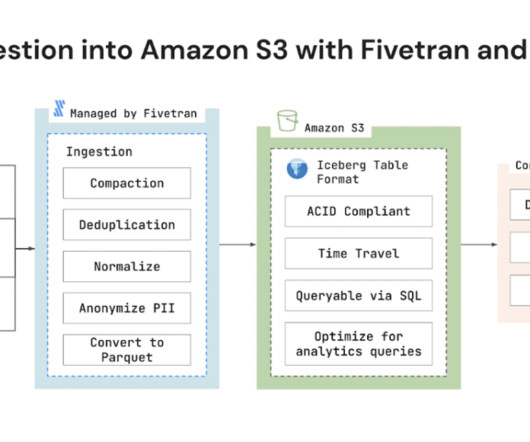
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
When you think of dataengineering , what comes to mind? In reality, though, if you use data (read: any information), you are most likely practicing some form of dataengineering every single day. Said differently, any tools or steps we use to help us utilize data can be considered dataengineering.
Introduction Microsoft Azure HDInsight(or Microsoft HDFS) is a cloud-based Hadoop Distributed File System version. A distributed file system runs on commodity hardware and manages massive data collections. It is a fully managed cloud-based environment for analyzing and processing enormous volumes of data.
Von Big Data über Data Science zu AI Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “S**t in, s**t out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW CloudData Hub (BMW’s datalake on AWS) and on-premises databases. He has a record of working with distributed teams across the globe within large enterprises.
Why start with a data source and build a visualization, if you can just find a visualization that already exists, complete with metadata about it? Data scientists went beyond database tables to datalakes and clouddata stores. Data scientists want to catalog not just information sources, but models.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Data mesh says architectures should be decentralized because there are inherent problems with centralized architectures.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Accenture calls it the Intelligent Data Foundation (IDF), and it’s used by dozens of enterprises with very complex data landscapes and analytic requirements. Simply put, IDF standardizes dataengineering processes. They can better understand data transformations, checks, and normalization.
With more data than ever before, the ability to find the right data has become harder than ever. Yet businesses need to find data to make data-driven decisions. However, dataengineers, data scientists, data stewards, and chief data officers face the challenge of finding data easily.
Qlik Replicate Qlik Replicate is a data integration tool that supports a wide range of source and target endpoints with configuration and automation capabilities that can give your organization easy, high-performance access to the latest and most accurate data. Replication of calculated values is not supported during Change Processing.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Furthermore, a shared-data approach stems from this efficient combination. What will You Attain with Snowflake?
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddata warehouse. Store this data in a customer data platform or datalake.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. We also need data profiling i.e. data discovery, to understand if the data is appropriate for ETL.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
Both persistent staging and datalakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer data pipeline. You might choose a clouddata warehouse like the Snowflake AI DataCloud or BigQuery. New user sign-up?
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before. What is a DataLake?
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads.
Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong data analytics capabilities. Amazon Redshift is a fully managed clouddata warehouse that trial scientists can use to perform analytics.
Chief Technology Officer, Information Technology Industry Survey respondents specified easier risk management and more data access to personnel as the top two benefits organizations can expect from moving data into a cloud platform.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content