This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are proud to announce two new analyst reports recognizing Databricks in the dataengineering and data streaming space: IDC MarketScape: Worldwide Analytic.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Dataengineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. DataEngineering Summit Our second annual DataEngineering Summit will be in-person for the first time! Learn more about them below.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of data scientists and dataengineers. Failing to make production data accessible in the cloud.
In recent years, dataengineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
With a traditional on-prem data warehouse, an organization will face more substantial Capital Expenditures (CapEx), or one-time costs, such as infrastructure setup, network configuration, and investments in servers and storage devices. When investing in a clouddata warehouse, the Operational Expenditures (OpEx) will be larger.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW CloudData Hub (BMW’s data lake on AWS) and on-premises databases. He works closely with enterprise customers to design data platforms and build advanced analytics and ML use cases.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Dataengineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need dataengineers. The journey to becoming a successful dataengineer […].
Fivetran Fivetran is a leading automated data integration service, providing businesses with an efficient way to move and centralize data from all their sources. Boasting nearly 500 pre-built data connectors, Fivetran simplifies transferring data to, from, and within any clouddata platform available today.
Accenture calls it the Intelligent Data Foundation (IDF), and it’s used by dozens of enterprises with very complex data landscapes and analytic requirements. Simply put, IDF standardizes dataengineering processes. IDF works natively on cloud platforms like AWS. How the IDF Supports a Smarter DataPipeline.
Why start with a data source and build a visualization, if you can just find a visualization that already exists, complete with metadata about it? Data scientists went beyond database tables to data lakes and clouddata stores. Data scientists want to catalog not just information sources, but models.
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. Dataengineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together.
However, the race to the cloud has also created challenges for data users everywhere, including: Cloud migration is expensive, migrating sensitive data is risky, and navigating between on-prem sources is often confusing for users. To build effective datapipelines, they need context (or metadata) on every source.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices.
Many dataengineering consulting companies could also answer these questions for you, or maybe you think you have the talent on your team to do it in-house. Many dataengineering consulting companies could also answer these questions for you, or maybe you think you have the talent on your team to do it in-house.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Use with caution, and test before committing to using them.
Founded in 2014 by three leading cloudengineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack. Data scientists.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipelineengine for streaming, CDC, and batch ingestion from any source to any destination. The biggest reason is the ease of use.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Furthermore, a shared-data approach stems from this efficient combination. Simplify and Win Experienced dataengineers value simplicity.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. Gateways are being used as another layer of security between Snowflake or clouddata source and Power BI users.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. And so that’s where we got started as a clouddata warehouse.
What’s really important in the before part is having production-grade machine learning datapipelines that can feed your model training and inference processes. And that’s really key for taking data science experiments into production. And so that’s where we got started as a clouddata warehouse.
Both persistent staging and data lakes involve storing large amounts of raw data. But persistent staging is typically more structured and integrated into your overall customer datapipeline. It’s not just a dumping ground for data, but a crucial step in your customer data processing workflow.
Tayo Olajide is a seasoned CloudDataEngineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments. Outside of work, he loves watching Formula1, playing badminton, and racing Go Karts.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. Matillion ETL for Snowflake is an ELT/ETL tool that allows for the ingestion, transformation, and building of analytics for data in the Snowflake AI DataCloud.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
In our previous blog , we discussed how Fivetran and dbt scale for any data volume and workload, both small and large. Now, you might be wondering what these tools can do for your data team and the efficiency of your organization as a whole. Can these tools help reduce the time our dataengineers spend fixing things?
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based data warehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























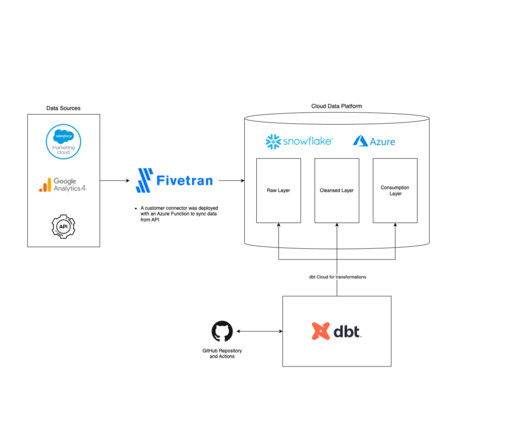












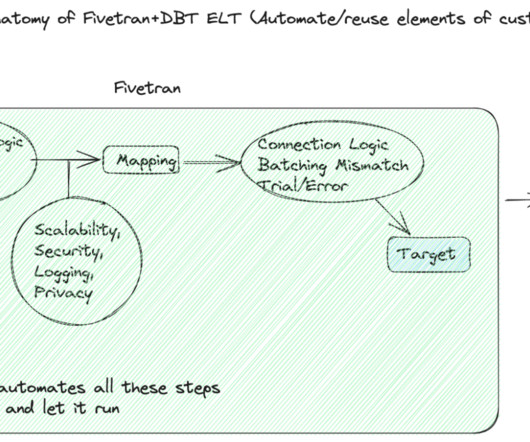







Let's personalize your content