This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? appeared first on Data Science Blog.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
With a traditional on-prem data warehouse, an organization will face more substantial Capital Expenditures (CapEx), or one-time costs, such as infrastructure setup, network configuration, and investments in servers and storage devices. When investing in a clouddata warehouse, the Operational Expenditures (OpEx) will be larger.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? A Note on the Shift from ETL to ELT.
It offers the advantage of having a single ETL platform to develop and maintain. It is well-suited for developing data systems that emphasize online learning and do not require a separate batch layer. The Kappa architecture is particularly suitable when event streaming or real-time processing use cases are predominant.
This expanded connector to Databricks Unity Catalog does just that, delivering to joint customers a comprehensive view of all clouddata. New Connectivity for dbt Modern dataengineers confront complex, challenging data environments and need to empower data users for self-service. Now with this new 2023.1
In recent years, dataengineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
As the latest iteration in this pursuit of high-quality data sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, data quality , and ETL/ELT. And it injects mature process control techniques from the world of traditional engineering. Take a look at figure 1 below.
Snowflake works with an entire ecosystem of tools including Extract Transform and Load (ETL), data integration, and analysis tools. Disaster Recovery Snowflake allows for an easy and automatic backup of data and enables faster disaster recovery of critical IT systems. Ready to Get Started in the Migration to Snowflake?
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the clouddata warehouse. But what does this mean from a practitioner perspective?
This may result in data inconsistency when UPDATE and DELETE operations are performed on the target database. For simple and quick replication to Snowflake, Matillion offers Data Loader, a SaaS tool that migrates data from various data sources. Replication of calculated values is not supported during Change Processing.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. Why Does it Matter? Contact phData today!
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
ThoughtSpot was designed to be low-code and easy for anyone to use across a business to generate insights and explore data. ThoughSpot can easily connect to top clouddata platforms such as Snowflake AI DataCloud , Oracle, SAP HANA, and Google BigQuery.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
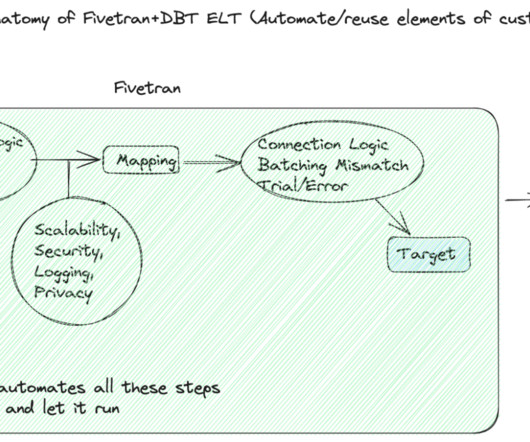
In our previous blog , we discussed how Fivetran and dbt scale for any data volume and workload, both small and large. Now, you might be wondering what these tools can do for your data team and the efficiency of your organization as a whole. Can these tools help reduce the time our dataengineers spend fixing things?
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content