This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
This article was published as a part of the Data Science Blogathon. Introduction We are all pretty much familiar with the common modern clouddatawarehouse model, which essentially provides a platform comprising a data lake (based on a cloud storage account such as Azure Data Lake Storage Gen2) AND a datawarehouse compute engine […].
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures?
Today, data controls a significant portion of our lives as consumers due to advancements in wireless connectivity, processing power, and […]. The post Advantages of Using CloudData Platform Snowflake appeared first on Analytics Vidhya.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddatawarehouse, delivering the best price-performance for your analytics workloads.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
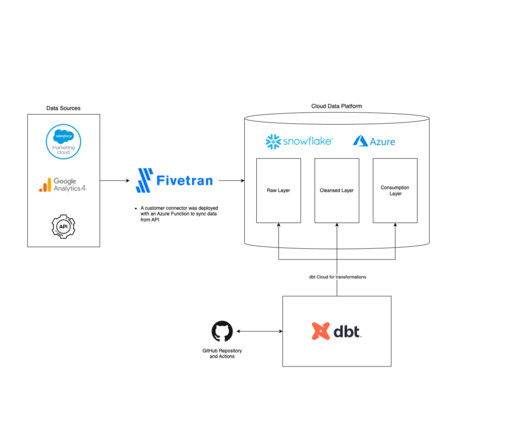
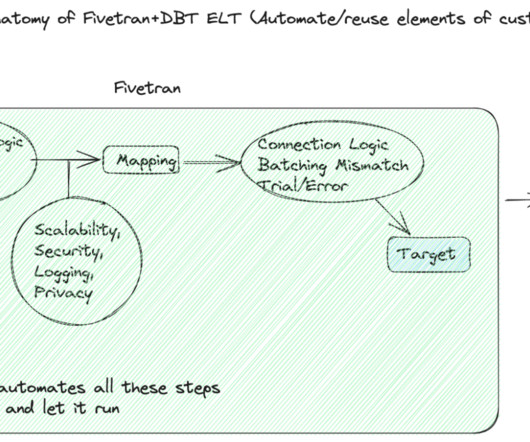
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. About the Authors Emrah Kaya is DataEngineering Manager at Omron Europe and Platform Lead for ODAP Project. Xinyi Zhou is a DataEngineer at Omron Europe, bringing her expertise to the ODAP team led by Emrah Kaya.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddatawarehouses and AI/ LLMs has transformed what businesses can do with data. What is the Modern Data Stack? Data modeling, data cleanup, etc.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices. What are Matillion's limitations?
With the advent of clouddatawarehouses and the ability to (seemingly) infinitely scale analytics on an organization’s data, centralizing and using that data to discover what drives customer engagement has become a top priority for executives across all industries and verticals.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
With the birth of clouddatawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data.
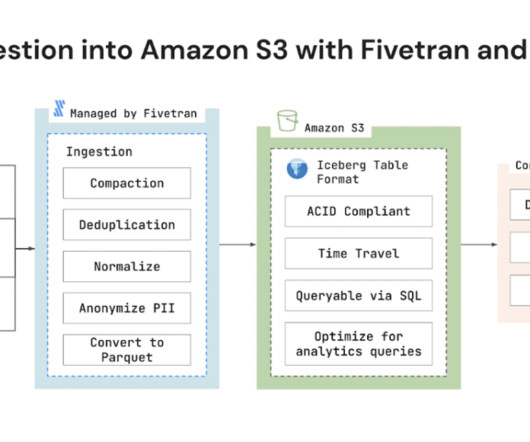
Customers who don’t necessarily want to put their data directly into a datawarehouse like the Snowflake DataCloud can now use Fivetran to build a performant, governed, managed dataset on top of S3 which can still be efficiently queried and manipulated from within their query engine of choice.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. That process will not take longer than 3 minutes!
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
Data analysts and engineers use dbt to transform, test, and document data in the clouddatawarehouse. Making this data visible in the data catalog will let data teams share their work, support re-use, and empower everyone to better understand and trust data.
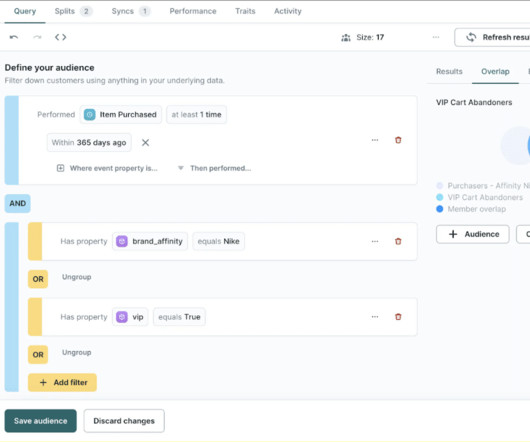
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. For behavioral data , Hightouch offers an event tracking SDK to deploy an SDK across your web, server, and mobile apps.
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. Dataengineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together.
Why You Should Consider Migrating from Netezza to Snowflake With Netezza, IBM was one of the first companies to provide a data warehousing solution to allow organizations to analyze and manage large amounts of data. However, as technology has evolved, the need for more advanced, agile data warehousing solutions has become apparent.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. It comprises three main areas: Landing area, Staging area, and DataWarehouse area.
. “We’re never going to be able to hire enough dataengineers, data scientists, and cloud architects to support the growth that we want to achieve. Transparency into data lineage and the data supply chain empowers people to know when data was first created, and who to ask for answers.
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
Founded in 2014 by three leading cloudengineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
These range from data sources , including SaaS applications like Salesforce; ELT like Fivetran; clouddatawarehouses like Snowflake; and data science and BI tools like Tableau. This expansive map of tools constitutes today’s modern data stack. But different users have different needs.
With Snowflake, data stewards have a choice to leverage Snowflake’s governance policies. First, stewards are dependent on datawarehouse admins to provide information and to create and edit enforcement policies in Snowflake. Alation’s data lineage helps organizations to secure their data in the Snowflake DataCloud.
In recent years, dataengineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
In our previous blog , we discussed how Fivetran and dbt scale for any data volume and workload, both small and large. Now, you might be wondering what these tools can do for your data team and the efficiency of your organization as a whole. Can these tools help reduce the time our dataengineers spend fixing things?
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the clouddatawarehouse. But what does this mean from a practitioner perspective?
Modern business operations rely heavily on dataengineering and transformation processes to turn raw data into valuable insights. Matillion, a robust ELT (Extract, Load, Transform) platform, simplifies data integration and transformation complexities with a no-code or high-code experience. What is a Matillion Job?
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content