This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Welcome to CloudData Science 7. Announcements around an exciting new open-source deep learning library, a new data challenge and more. Amazon Personalize can now use 10x more item attributes Personalize, which is a customizable recommendation engine, can now use 50 attributes instead of just 5. Training and Courses.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? appeared first on Data Science Blog.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
Simple Data Model for a Process Mining Event Log As part of dataengineering, the data traces that indicate process activities are brought into a log-like schema. A simple event log is therefore a simple table with the minimum requirement of a process number (case ID), a time stamp and an activity description.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
Data Warehousing ist seit den 1980er Jahren die wichtigste Lösung für die Speicherung und Verarbeitung von Daten für Business Intelligence und Analysen. Mit der zunehmenden Datenmenge und -vielfalt wurde die Verwaltung von Data Warehouses jedoch immer schwieriger und teurer.
Celonis unterscheidet sich von den meisten anderen Tools noch dahingehend, dass es versucht, die ganze Kette des Process Minings in einer einzigen und ausschließlichen Cloud-Anwendung in einer Suite bereitzustellen. Vielleicht haben wir auch das ein Stück weit Celonis zu verdanken. Aber auch andere Prozesse für andere Geschäftsprozesse z.
There are several styles of data integration. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. What is the Modern Data Stack? Data modeling, data cleanup, etc.
Dataengineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need dataengineers. The journey to becoming a successful dataengineer […].
A prime example of this is automating repetitive code performed in many models or implementing a new feature introduced in your clouddata warehouse. Scenarios Now, we need to build the SQL statements. In this case, we have to create it before loading the data. In our case, we need to set up the temporary table SQL first.
In recent years, dataengineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
However, many analysts and other data professionals run into two common problems: They are not given direct access to their database They lack the skills in SQL to write the queries themselves The traditional solution to these problems is to rely on IT and dataengineering teams. Only use the data you need.
The SnowPro Advanced Administrator Certification targets Snowflake Administrators, Snowflake DataCloud Administrators, Database Administrators, Cloud Infrastructure Administrators, and CloudData Administrators. I found the DataEngineering Simplified’s playlists particularly beneficial during my studies.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Below are the best practices.
Profiling delivers a birds-eye view of the statistics of the data, such as minimum, maximum, median, and null values. This empowers users to judge data’s quality and fitness for purpose quickly. This expanded connector to Databricks Unity Catalog does just that, delivering to joint customers a comprehensive view of all clouddata.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
Utilizing AI and machine learning (ML) models can sound like a daunting task, but it is achievable, especially with the ML engineering experts at phData by your side to guide you in your data journey. Many dataengineering consulting companies can answer these questions, and you may have the in-house talent to do it yourself.
Organizations must ensure their data pipelines are well designed and implemented to achieve this, especially as their engagement with clouddata platforms such as the Snowflake DataCloud grows. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable data pipelines.
Cleaning and preparing the data Raw data typically shouldn’t be used in machine learning models as it’ll throw off the prediction. Dataengineers can prepare the data by removing duplicates, dealing with outliers, standardizing data types and precision between data sets, and joining data sets together.
This data can help healthcare providers retain their key talent and save hundreds of thousands of dollars in yearly recruiting costs. Many dataengineering consulting companies could also answer these questions for you, or maybe you think your team has the talent to do it in-house. Why phData?
It comes with a rather lightweight intellisense, and highlights for both SQL and Jinja use. The real power is the ability to run your models and view the outputs, or even have your SQL compiled to verify that your Jinja or SQL compiles into the correct model. Our team of data experts are happy to assist. Reach out today!
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. And once again, for loading data, do not use SQL Inserts.
Data Sharing Enterprises can easily create data sharing relationships with direct, governed, and secure sharing in near-real time. With Snowflake, organizations can be data consumers, data providers, or both. Ready to Get Started in the Migration to Snowflake?
Data warehousing is a vital constituent of any business intelligence operation. Companies can build Snowflake databases expeditiously and use them for ad-hoc analysis by making SQL queries. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode.
Proper data preparation leads to better model performance and more accurate predictions. SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. The following diagram shows the SageMaker Canvas data flow after adding visual transformations.
Many dataengineering consulting companies could also answer these questions for you, or maybe you think you have the talent on your team to do it in-house. Expertise Here at phData, we strive to be experts in dataengineering, analytics, and machine learning. Why phData? Why should you choose phData to help?
Organizations need to ensure that data use adheres to policies (both organizational and regulatory). In an ideal world, you’d get compliance guidance before and as you use the data. Imagine writing a SQL query or using a BI dashboard with flags & warnings on compliance best practice within your natural workflow.
Founded in 2014 by three leading cloudengineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
These range from data sources , including SaaS applications like Salesforce; ELT like Fivetran; clouddata warehouses like Snowflake; and data science and BI tools like Tableau. This expansive map of tools constitutes today’s modern data stack. But different users have different needs.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Savings may vary depending on configurations, workloads and vendor.
ThoughtSpot is a cloud-based AI-powered analytics platform that uses natural language processing (NLP) or natural language query (NLQ) to quickly query results and generate visualizations without the user needing to know any SQL or table relations. Why Use ThoughtSpot?
Matillion Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into clouddata environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the clouddata warehouse. But what does this mean from a practitioner perspective?
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddata warehouse.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a dataengineering team), who manage and transform data for wider consumption. But why is such an inversion needed?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










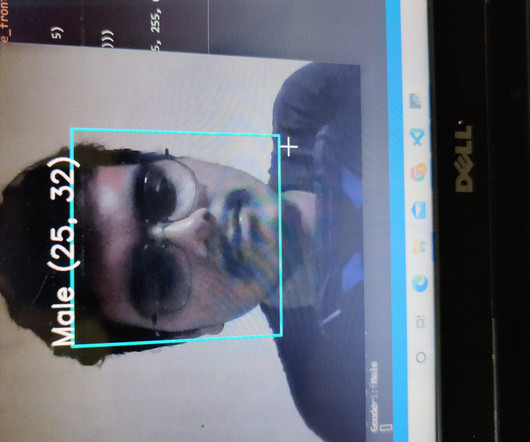






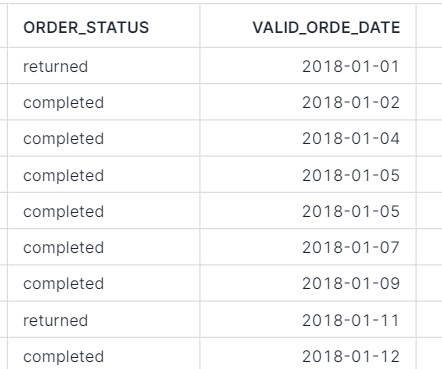

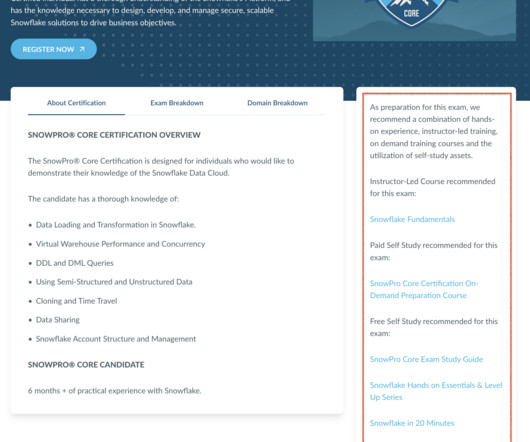



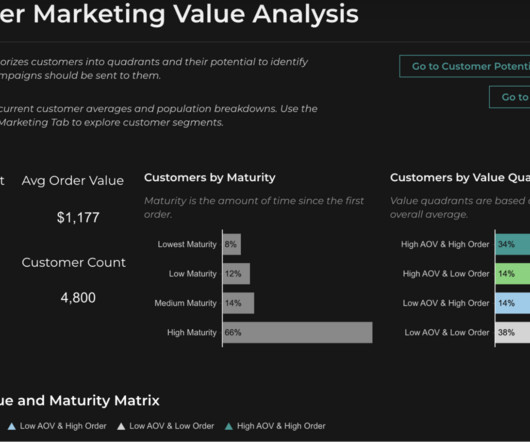


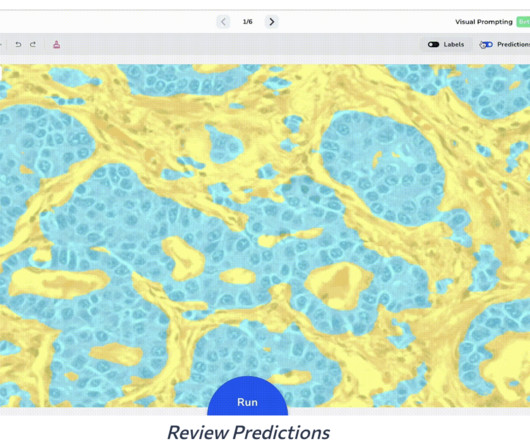
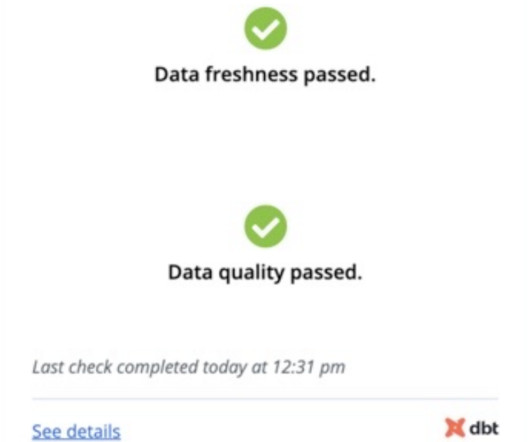





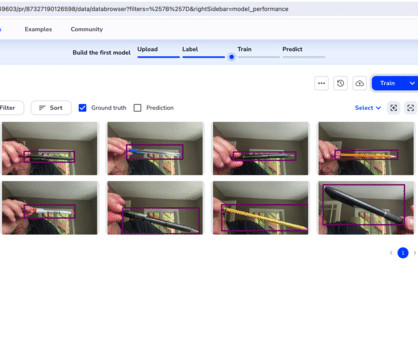
















Let's personalize your content