This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction We are all pretty much familiar with the common modern clouddatawarehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a datawarehouse compute engine […].
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While datawarehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The term and its underlying technology have been thriving more than ever.
In today’s world, datawarehouses are a critical component of any organization’s technology ecosystem. The rise of cloud has allowed datawarehouses to provide new capabilities such as cost-effective data storage at petabyte scale, highly scalable compute and storage, pay-as-you-go pricing and fully managed service delivery.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake.
The post DataLakes for Non-Techies appeared first on DATAVERSITY. Moreover, complex usability helped in developing a network of certified (aka expensive and lucrative) consultancy workforce. IT has recently experienced […].
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddatawarehouse, delivering the best price-performance for your analytics workloads.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before. What is a DataLake?
Snowflake provides the right balance between the cloud and data warehousing, especially when datawarehouses like Teradata and Oracle are becoming too expensive for their users. It is also easy to get started with Snowflake as the typical complexity of datawarehouses like Teradata and Oracle are hidden from the users. .
It is comprised of commodity cloud object storage, open data and open table formats, and high-performance open-source query engines. To help organizations scale AI workloads, we recently announced IBM watsonx.data , a data store built on an open data lakehouse architecture and part of the watsonx AI and data platform.
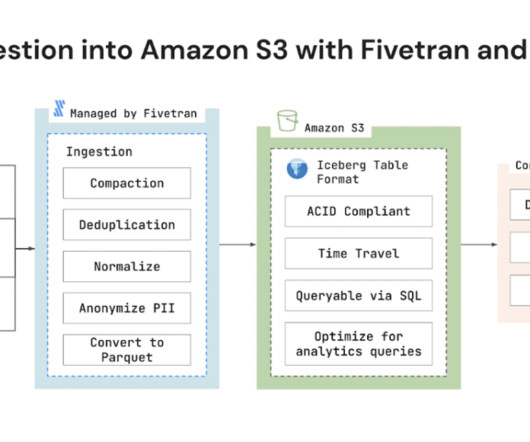
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudDatawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQL DataWarehouse and Azure DataLake. Azure Synapse.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, Machine Learning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
According to Gartner, data fabric is an architecture and set of data services that provides consistent functionality across a variety of environments, from on-premises to the cloud. Data fabric simplifies and integrates on-premises and cloudData Management by accelerating digital transformation.
Define data ownership, access controls, and data management processes to maintain the integrity and confidentiality of your data. Data integration: Integrate data from various sources into a centralized clouddatawarehouse or datalake.
With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments. Savings may vary depending on configurations, workloads and vendors.
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
Amazon Redshift is the most popular clouddatawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Compliance in the Cloud ( GDPR, CCPA ) is still in in its infancy and tough to navigate, with people wondering: How do you manage policies in the cloud? How do you provide access and connect the right people to the right data? AWS has created a way to manage policies and access, but this is only for datalake formation.
The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency.
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 datalake, Snowflake clouddatawarehouse and Tableau (and how it can be fixed). And connectivity is the crux of a powerful data catalog.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
Data modernization is the process of transferring data to modern cloud-based databases from outdated or siloed legacy databases, including structured and unstructured data. In that sense, data modernization is synonymous with cloud migration. 5 Benefits of Data Modernization. Advanced Tooling.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
There are three potential approaches to mainframe modernization: Data Replication creates a duplicate copy of mainframe data in a clouddatawarehouse or datalake, enabling high-performance analytics virtually in real time, without negatively impacting mainframe performance.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data.
Traditionally, organizations built complex data pipelines to replicate data. Those data architectures were brittle, complex, and time intensive to build and maintain, requiring data duplication and bloated datawarehouse investments. Salesforce DataCloud for Tableau solves those challenges.
Co-location data centers: These are data centers that are owned and operated by third-party providers and are used to house the IT equipment of multiple organizations. What are the similarities and differences between data centers, datalake houses, and datalakes? Not a cloud computer?
Focus Area ETL helps to transform the raw data into a structured format that can be easily available for data scientists to create models and interpret for any data-driven decision. A data pipeline is created with the focus of transferring data from a variety of sources into a datawarehouse.
We have an explosion, not only in the raw amount of data, but in the types of database systems for storing it ( db-engines.com ranks over 340) and architectures for managing it (from operational datastores to datalakes to clouddatawarehouses). Organizations are drowning in a deluge of data.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data pipeline orchestration.
The rush to become data-driven is more heated, important, and pronounced than it has ever been. Businesses understand that if they continue to lead by guesswork and gut feeling, they’ll fall behind organizations that have come to recognize and utilize the power and potential of data. Click to learn more about author Mike Potter.
This announcement is interesting and causes some of us in the tech industry to step back and consider many of the factors involved in providing data technology […]. The post Where Is the Data Technology Industry Headed? Click here to learn more about Heine Krog Iversen.
However, most enterprises are hampered by data strategies that leave teams flat-footed when […]. The post Why the Next Generation of Data Management Begins with Data Fabrics appeared first on DATAVERSITY. Click to learn more about author Kendall Clark. The mandate for IT to deliver business value has never been stronger.
There are many different third-party tools that work with Snowflake: Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance datawarehouse, such as Snowflake.
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddatawarehouse. Store this data in a customer data platform or datalake.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
The semantic layer concept within the data stack is not new but is an increasingly popular topic of conversation. I predict that in 2022, we’ll see mainstream awareness of the semantic layer, especially as enterprises begin to see real-world examples of its benefits.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content