This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Welcome to the first beta edition of CloudData Science News. This will cover major announcements and news for doing data science in the cloud. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing.
For many enterprises, a hybrid clouddatalake is no longer a trend, but becoming reality. With a cloud deployment, enterprises can leverage a “pay as you go” model; reducing the burden of incurring capital costs. The Problem with Hybrid Cloud Environments. How to Catalog AWS S3 with Alation. Conclusion.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure DataLake. Azure Synapse. It’s true, I saw it happen this week.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudData warehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Open source big data tools like Hadoop were experimented with – these could land data into a repository first before transformation. Thus, the early datalakes began following more of the EL-style flow. Snowflake was optimized for the cloud, separating storage and computing.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Replicate can interact with a wide variety of databases, data warehouses, and datalakes (on-premise or based in the cloud). It is also a helpful tool for learning a new SQL dialect.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. 1 When comparing published 2023 list prices normalized for VPC hours of watsonx.data to several major clouddata warehouse vendors.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. And once again, for loading data, do not use SQL Inserts.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Data warehousing is a vital constituent of any business intelligence operation. What will You Attain with Snowflake?
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data pipeline orchestration.
Qlik Replicate Qlik Replicate is a data integration tool that supports a wide range of source and target endpoints with configuration and automation capabilities that can give your organization easy, high-performance access to the latest and most accurate data. Replication of calculated values is not supported during Change Processing.
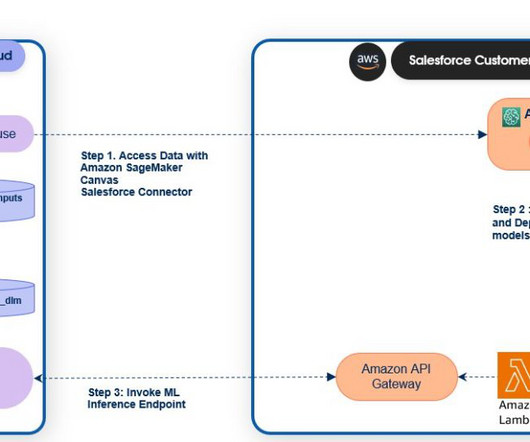
Choose Run SQL query and take note of the API Gateway URL and schema because you will need this information when registering with Einstein Studio. Data Architect, DataLake & AI/ML, serving strategic customers. Copy and paste the link into a new browser tab URL. Let’s look at the file without downloading it.
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddata warehouse. Store this data in a customer data platform or datalake.
Some modern CDPs are starting to incorporate these concepts, allowing for more flexible and evolving customer data models. It also requires a shift in how we query our customer data. Instead of simple SQL queries, we often need to use more complex temporal query languages or rely on derived views for simpler querying.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
A simple model to control access to data via a UI or SQL. Automatically tracking data lineage across queries executed in any language. To ensure you can deliver on this world-changing vision of data, Alation helps you maximize the value of your datalake with integrations to the Unity catalog. and much more!
Set up OAuth for Salesforce DataCloud in SageMaker Canvas. Connect to Salesforce DataClouddata using the built-in SageMaker Canvas Salesforce DataCloud connector and import the dataset. Configure the following scopes on your connected app: Manage user data via APIs ( api ).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content