This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Database name : Enter dev. Database user : Enter awsuser. Conclusion We believe integrating your clouddata warehouse (Amazon Redshift) with SageMaker Canvas opens the door to producing many more robust ML solutions for your business at faster and without needing to move data and with no ML experience.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
A data fabric is textured approach to combining disparate data sources, datapipelines, databases, data streams and clouddata services into one woven unified entity.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms. We will specifically focus on how to enable it for the Snowflake cloud platform, taking into consideration the account and schema-level object hierarchy.
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
As the global cloud computing market is projected to grow from USD 626.4 Defining Cloud Computing in Data Science Cloud computing provides on-demand access to computing resources such as servers, storage, databases, and software over the Internet. billion in 2023 to USD 1,266.4
Google BigQuery is a serverless and cost-effective multi-clouddata warehouse. Druid is a real-time analytics database from Apache. It is a high-performing database that is designed to build fast, modern data applications. Google BigQuery. It is designed for business agility, and that is why it is highly scalable.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW CloudData Hub (BMW’s data lake on AWS) and on-premises databases.
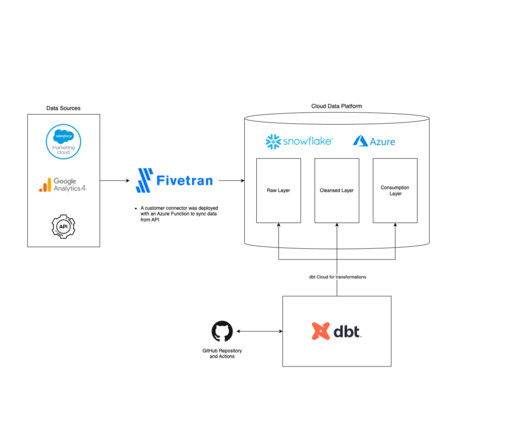
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. This includes most of the popular cloud object storage along with several options that on-premises can use, such as FTP/sFTP.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Fortunately, a modern data stack (MDS) using Fivetran, Snowflake, and Tableau makes it easier to pull data from new and various systems, combine it into a single source of truth, and derive fast, actionable insights. What is a modern data stack? Transparency .
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. This includes users, roles, schemas, databases, and warehouses.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. Database names, Cloud Region, etc.
Manage data with a seamless, consistent design experience – no need for complex coding or highly technical skills. Simply design datapipelines, point them to the cloud environment, and execute. What does all this mean for your business?
When the data or pipeline configuration needs to be changed, tools like Fivetran and dbt reduce the time required to make the change, and increase the confidence your team can have around the change. These allow you to scale your pipelines quickly. Governance doesn’t have to be scary or preventative to your clouddata warehouse.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
Today, clouddata platforms like Snowflake, Databricks, Amazon Redshift, and others have changed the game. With a publish-subscribe architecture, various enterprise applications can make real-time data available, and other applications and platforms can consume the information as needed.
Powerful data integration capabilities bridge the gap between mainframe systems and cloud platforms, replicating changes on the mainframe to clouddata platforms and on-premise databases in real time. Containerization Docker containers are revolutionizing the way organizations host and deply applications.
Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Having been built completely for and in the cloud, the Snowflake DataCloud has become an industry leader in clouddata platforms.
Why start with a data source and build a visualization, if you can just find a visualization that already exists, complete with metadata about it? Data scientists went beyond database tables to data lakes and clouddata stores. Data scientists want to catalog not just information sources, but models.
The right data integration technology can vastly simplify things. Together with other data integrity tools, you can maintain the accuracy, completeness, and quality of data over its lifecycle. Streaming datapipelines help to make data available and accessible in real time.
As enterprise technology landscapes grow more complex, the role of data integration is more critical than ever before. Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? The rise of cloud computing and clouddata warehousing has catalyzed the growth of the modern data stack.
They created each capability as modules, which can either be used independently or together to build automated datapipelines. IDF works natively on cloud platforms like AWS. In essence, Alation is acting as a foundational data fabric that Gartner describes as being required for DataOps.
From structured data sources like ERPs, CRM, and relational data stores to unstructured data such as PDFs, images, and videos, enterprises are confronted with the daunting challenge of keeping up with their ever-expanding data ecosystem.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Datapipeline orchestration.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular clouddata warehouses like Snowflake can provide the scalability needed as your business grows.
As data and AI continue to dominate today’s marketplace, the ability to securely and accurately process and centralize that data is crucial to an organization’s long-term success. Fivetran’s Hybrid Architecture allows an organization to maintain ownership and control of its data through the entire datapipeline.
This process enables businesses to consolidate data from different platforms, ensuring it’s ready for analysis and decision-making. The first step in the ETL process is extraction, where data is gathered from different sources, such as databases, cloud services, or flat files.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world data engineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
Through workload optimization across multiple query engines and storage tiers, organizations can reduce data warehouse costs by up to 50 percent. 1 Watsonx.data offers built-in governance and automation to get to trusted insights within minutes, and integrations with existing databases and tools to simplify setup and user experience.
Having gone public in 2020 with the largest tech IPO in history, Snowflake continues to grow rapidly as organizations move to the cloud for their data warehousing needs. Importing data allows you to ingest a copy of the source data into an in-memory database.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content