This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
However, efficient use of ETLpipelines in ML can help make their life much easier. This article explores the importance of ETLpipelines in machine learning, a hands-on example of building ETLpipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
In recent years, data engineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
With a traditional on-prem data warehouse, an organization will face more substantial Capital Expenditures (CapEx), or one-time costs, such as infrastructure setup, network configuration, and investments in servers and storage devices. When investing in a clouddata warehouse, the Operational Expenditures (OpEx) will be larger.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
If you haven’t already, moving to the cloud can be a realistic alternative. Clouddata warehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data. Datapipeline maintenance.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake.
Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? A Note on the Shift from ETL to ELT.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
The story is all too common – a business user requests some data, the data team creates/prioritizes a ticket, and said ticket is completed after some number of months (or weeks if you’re lucky) – just to have the data be wrong, and the whole process starts again. Those are scary for data teams to change.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Why Does it Matter?
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. The right data integration technology can vastly simplify things. Streaming datapipelines help to make data available and accessible in real time.
Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Having been built completely for and in the cloud, the Snowflake DataCloud has become an industry leader in clouddata platforms.
Matillion’s Data Productivity Cloud is a versatile platform designed to increase the productivity of data teams. It provides a unified platform for creating and managing datapipelines that are effective for both coders and non-coders. With that, you can cover most of the necessary connections.
As the latest iteration in this pursuit of high-quality data sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, data quality , and ETL/ELT. They created each capability as modules, which can either be used independently or together to build automated datapipelines.
The sudden popularity of clouddata platforms like Databricks , Snowflake , Amazon Redshift, Amazon RDS, Confluent Cloud , and Azure Synapse has accelerated the need for powerful data integration tools that can deliver large volumes of information from transactional applications to the cloud reliably, at scale, and in real time.
However, the race to the cloud has also created challenges for data users everywhere, including: Cloud migration is expensive, migrating sensitive data is risky, and navigating between on-prem sources is often confusing for users. To build effective datapipelines, they need context (or metadata) on every source.
The sudden popularity of clouddata platforms like Databricks , Snowflake , Amazon Redshift, Amazon RDS, Confluent Cloud , and Azure Synapse has accelerated the need for powerful data integration tools that can deliver large volumes of information from transactional applications to the cloud reliably, at scale, and in real time.
Source data formats can only be Parquer, JSON, or Delimited Text (CSV, TSV, etc.). Streamsets Data Collector StreamSets Data Collector Engine is an easy-to-use datapipeline engine for streaming, CDC, and batch ingestion from any source to any destination.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
Replicate can interact with a wide variety of databases, data warehouses, and data lakes (on-premise or based in the cloud). Migrating Your Pipelines and Code It’s more than likely that your business has years of code being used in its datapipelines.
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETLpipelines that cause decisions to be made on stale or old data.
The next generation of Db2 Warehouse SaaS and Netezza SaaS on AWS fully support open formats such as Parquet and Iceberg table format, enabling the seamless combination and sharing of data in watsonx.data without the need for duplication or additional ETL. Savings may vary depending on configurations, workloads and vendor.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
While we haven’t built technology that enables real-time matter transfer yet, modern science is pursuing concepts like superposition and quantum teleportation to facilitate information transfer across any distance […] The post 10 Advantages of Real-Time Data Streaming in Commerce appeared first on DATAVERSITY.
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
Last week, the Alation team had the privilege of joining IT professionals, business leaders, and data analysts and scientists for the Modern Data Stack Conference in San Francisco. In “The modern data stack is dead, long live the modern data stack!” Cloud costs are growing prohibitive.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















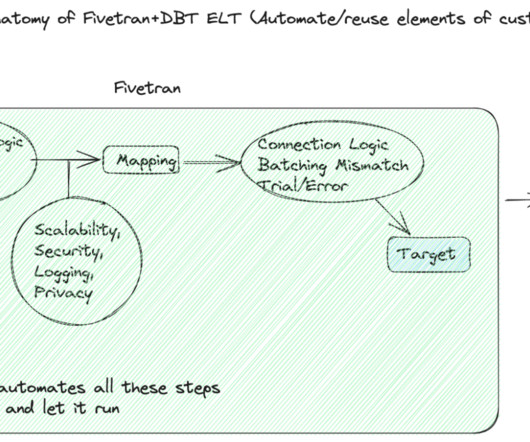



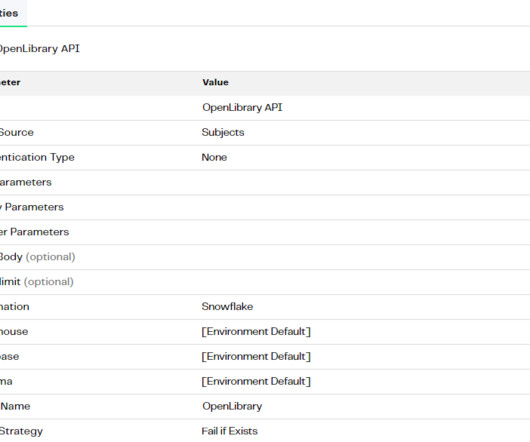




















Let's personalize your content