This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As enterprises migrate to the cloud, two key questions emerge: What’s driving this change? And what must organizations overcome to succeed at clouddata warehousing ? What Are the Biggest Drivers of CloudData Warehousing? Yet the cloud, according to Sacolick, doesn’t come cheap. “A Migrate What Matters.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
Amazon Redshift is the most popular clouddatawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. With this Spark connector, you can easily ingest data to the feature group’s online and offline store from a Spark DataFrame.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
Data Scientist: The Predictive Powerhouse The pure data scientists are the most demanded within all the Data Science career paths. This definition specifically describes the Data Scientist as being the predictive powerhouse of the data science ecosystem.
If you haven’t already, moving to the cloud can be a realistic alternative. Clouddatawarehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data. You can’t afford to waste their time on a few reports.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. It could be gross margin.
With the birth of clouddatawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
People need to be able to add related data to their analysis so they can consider additional variables, which often leads to more impactful insights. Adding more data also lets people tell the data story their way – the very definition of being data driven.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. In the modern data stack, dbt is a key tool to make data ready for analysis. Improve data analysis accuracy.
Snowflake AI DataCloud has become a premier clouddata warehousing solution. Maybe you’re just getting started looking into a cloud solution for your organization, or maybe you’ve already got Snowflake and are wondering what features you’re missing out on.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data pipeline orchestration.
These range from data sources , including SaaS applications like Salesforce; ELT like Fivetran; clouddatawarehouses like Snowflake; and data science and BI tools like Tableau. This expansive map of tools constitutes today’s modern data stack.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. Gateways are being used as another layer of security between Snowflake or clouddata source and Power BI users.
Data intelligence has thus evolved to answer these questions, and today supports a range of use cases. Examples of Data Intelligence use cases include: Data governance. Cloud Transformation. CloudData Migration. Let’s take a closer look at the role of DI in the use case of data governance.
Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. Additional setup is typically optional.
The advantages of mixing R code for some unique libraries and Python code for more general data frame access with common display graphics for both is a big leap forward. Cloud-to-CloudData Performance 10 3 to 10 6 Faster. DataRobot Zepl operates 100% in the cloud. This is not an imaginary issue.
Set aside some time to experiment with dbt Cloud based on what you’ve learned in the courses. To do this, you’ll need to create a free dbt account , a Snowflake trial account (or another DataWarehouse), and a GitHub account. Consider it an additional resource in your preparation process. Know when they are updated.
Data fabric is now on the minds of most data management leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The data catalog is a foundational layer of the data fabric. ” 1.
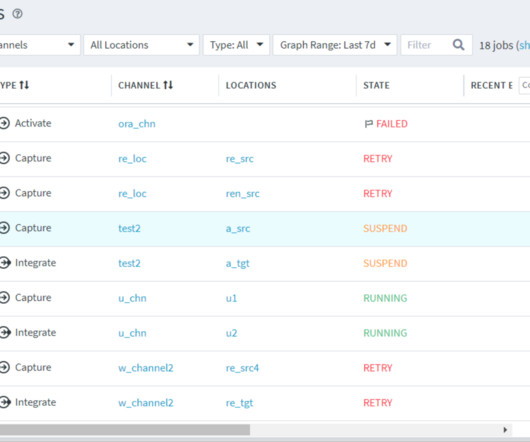
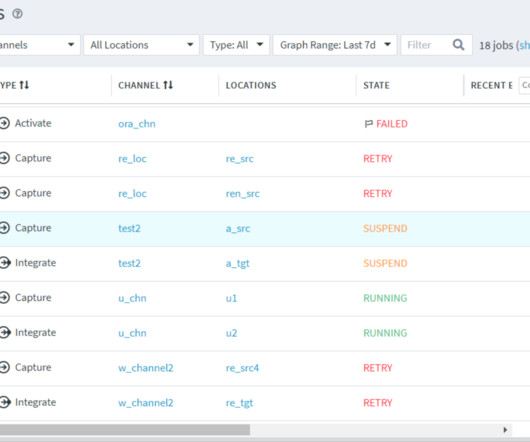
LDP Locations In Fivetran’s LDP, a location refers to a specific storage space (database or file storage) where it can replicate data from a source location or storage space where LDP can replicate data to the Target location. WAITING : This state indicates that the job will run at a scheduled time.
LDP (HVR) Locations In Fivetran’s LDP (HVR), a location refers to a specific storage space (database or file storage) where it can replicate data from a source location or storage space where LDP (HVR) can replicate data to the Target location. WAITING : This state indicates that the job will run at a scheduled time.
Users must be able to access data securely — e.g., through RBAC policy definition. Readers may notice these attributes echo other data management frameworks. The ‘ FAIR Guiding Principles for scientific data management and stewardship ’ is one such framework. Secure and governed by a global access control.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
All this raw data goes into your persistent stage. Then, if you later refine your definition of what constitutes an “engaged” customer, having the raw data in persistent staging allows for easy reprocessing of historical data with the new logic. Are people binge-watching your original series?
Its functionality comprises standing as an intermediary between raw data and visualizations and, thereby, acts as the place to facilitate ease of data exploration and analysis. It represents a centralized, shared datadefinition, allowing aggregations and other transformations. Select Dataset from the dropdown menu.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content