This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures?
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
Text analytics: Text analytics, also known as text mining, deals with unstructured text data, such as customer reviews, social media comments, or documents. It uses natural language processing (NLP) techniques to extract valuable insights from textual data. Poor data integration can lead to inaccurate insights.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex data pipelines.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management. Data transformation.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddatawarehouse like Snowflake. Document business rules and assumptions directly within the workflow. Data tables used and their role in the workflow.
is not just for data scientists and developers — business users can also access it via an easy-to-use interface that responds to natural language prompts for different tasks. With watsonx.data , businesses can quickly connect to data, get trusted insights and reduce datawarehouse costs. Watsonx.ai
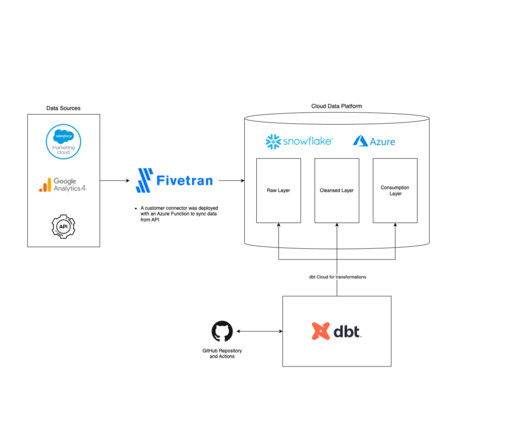
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency.
“ Vector Databases are completely different from your clouddatawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. When documents are split into smaller chunks, search systems can find relevant sections more precisely and quickly.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Lineage helps them identify the source of bad data to fix the problem fast. Manual lineage will give ARC a fuller picture of how data was created between AWS S3 data lake, Snowflake clouddatawarehouse and Tableau (and how it can be fixed). Time is money,” said Leonard Kwok, Senior Data Analyst, ARC.
With the birth of clouddatawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
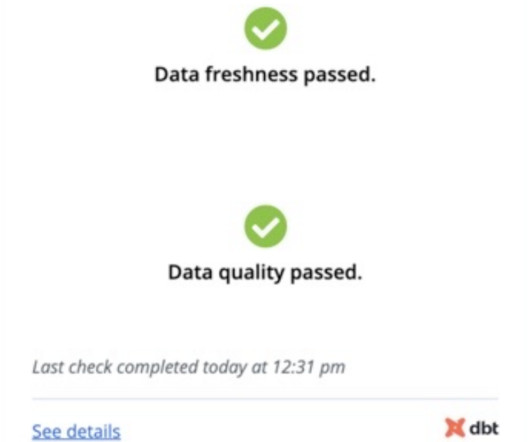
Hosted Doc Site for Documentation One of the most powerful features of dbt can be the documentation you generate. This documentation can give different users insight into where data came from, what the profile of the data is, what the SQL looked like, and the DAG to know where the data is being used.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. That process will not take longer than 3 minutes!
Amazon Redshift is a fully managed, fast, secure, and scalable clouddatawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. She is passionate about data-driven AI and the area of depth in machine learning.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
States’ existing investments in modernizing and enhancing ancillary supportive technologies (such as document management, web portals, mobile applications, datawarehouses and location services) could negate the need for certain system requirements as part of the child support system modernization initiative.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the clouddatawarehouse. But what does this mean from a practitioner perspective?
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular clouddatawarehouses like Snowflake can provide the scalability needed as your business grows.
It simply wasn’t practical to adopt an approach in which all of an organization’s data would be made available in one central location, for all-purpose business analytics. To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
improved document management capabilities, web portals, mobile applications, datawarehouses, enhanced location services, etc.) .” For example, the core systems technology landscape for each state could be a mainframe legacy system with varying degrees of maturity, portability, reliability and scalability.
This two-part series will explore how data discovery, fragmented data governance , ongoing data drift, and the need for ML explainability can all be overcome with a data catalog for accurate data and metadata record keeping. The CloudData Migration Challenge. Data pipeline orchestration.
To date, the company’s data warehousing solutions are largely built from the same template used in 1979. In short, they are still the model of multiple processors and massive disk storage with datawarehouse software on the top layer managing it all.
They provide loose coupling between the business logic that processes your data and the platform and data that it is executed upon. With Fivetran, you can quickly and easily switch between different datawarehouse technologies in which to land your data, as well as popular open-source lake formats such as Apache Iceberg.
With Snowflake, data stewards have a choice to leverage Snowflake’s governance policies. First, stewards are dependent on datawarehouse admins to provide information and to create and edit enforcement policies in Snowflake. Alation’s data lineage helps organizations to secure their data in the Snowflake DataCloud.
We have an explosion, not only in the raw amount of data, but in the types of database systems for storing it ( db-engines.com ranks over 340) and architectures for managing it (from operational datastores to data lakes to clouddatawarehouses). Organizations are drowning in a deluge of data.
dbt Labs is a robust platform that allows individuals comfortable with SQL to incorporate software engineering’s best practices into their data transformation pipelines. These practices encompass aspects such as code versioning, testing, documentation, and modular programming. Know when they are updated.
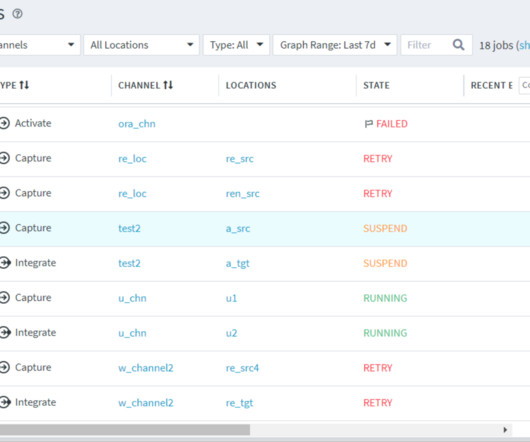
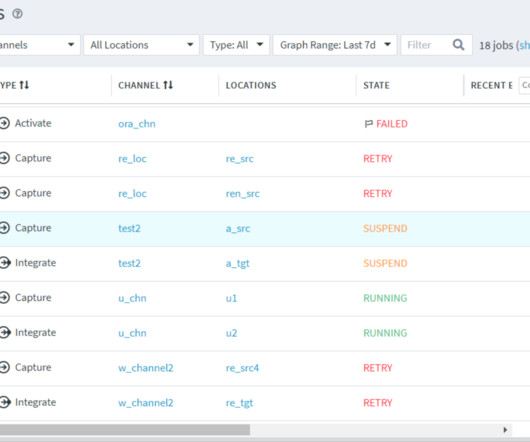
LDP Locations In Fivetran’s LDP, a location refers to a specific storage space (database or file storage) where it can replicate data from a source location or storage space where LDP can replicate data to the Target location. For more information on HVA, visit the official documentation. Image from FiveTran documentation.
LDP (HVR) Locations In Fivetran’s LDP (HVR), a location refers to a specific storage space (database or file storage) where it can replicate data from a source location or storage space where LDP (HVR) can replicate data to the Target location. For more information on HVA, visit the official documentation.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. In the modern data stack, dbt is a key tool to make data ready for analysis.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. For more information on composite models, check out Microsoft’s official documentation.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world data engineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading clouddata platform.
Matillion is also built for scalability and future data demands, with support for clouddata platforms such as Snowflake DataCloud , Databricks, Amazon Redshift, Microsoft Azure Synapse, and Google BigQuery, making it future-ready, everyone-ready, and AI-ready. Check out the API documentation for our sample.
Data analysts spent many hours converting assets into reports or refactoring them in more graphic native tools, such as Tableau. By implementing open source notebooks like Jupyter in a browser, data science can join programming, some documentation (using Markdown), tables, and graphics all in the same environment.
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your clouddatawarehouse. However, targeted web advertising may only require linkage to a browser or device ID.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. The single most common way to create a view in a dataset is by CREATE VIEW DDL statement and you can refer to the official documentation to explore more options.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Much of these greenhouse gas emissions can be attributed to travel (such as air travel, hotel, meetings), distribution associated for drugs and documents, and electricity used in coordination centers. Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong data analytics capabilities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content