This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: CloudDataWarehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for CloudData Infrastructures?
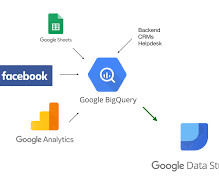
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-clouddatawarehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
It’s also possible to employ extra caching or materialized views in the datawarehouse in addition to caching in Looker (depending on the capability of your datawarehouse). One added tip is to aggregate your data before loading it into Looker or in the datawarehouse to reduce the amount of data loaded onto the platform.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Dating back to the 1970s, the data warehousing market emerged when computer scientist Bill Inmon first coined the term ‘datawarehouse’. Created as on-premise servers, the early datawarehouses were built to perform on just a gigabyte scale. The post How Will The Cloud Impact Data Warehousing Technologies?
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and data pipelines just aren't agile enough.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQLDataWarehouse and Azure Data Lake. Azure Synapse. It’s true, I saw it happen this week.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management. Data transformation.
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads. Click on the Create New button in the upper left-hand corner.
Celonis unterscheidet sich von den meisten anderen Tools noch dahingehend, dass es versucht, die ganze Kette des Process Minings in einer einzigen und ausschließlichen Cloud-Anwendung in einer Suite bereitzustellen. Vielleicht haben wir auch das ein Stück weit Celonis zu verdanken. Aber auch andere Prozesse für andere Geschäftsprozesse z.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddatawarehouses and AI/ LLMs has transformed what businesses can do with data. Designed to cheaply and efficiently process large quantities of data.
Amazon Redshift is the most popular clouddatawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Watsonx.data will allow users to access their data through a single point of entry and run multiple fit-for-purpose query engines across IT environments. Through workload optimization an organization can reduce datawarehouse costs by up to 50 percent by augmenting with this solution. [1]
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Datawarehouses and data lakes feel cumbersome and data pipelines just aren't agile enough.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudDatawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
With ELT, we first extract data from source systems, then load the raw data directly into the datawarehouse before finally applying transformations natively within the datawarehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. It offers a cloud-agnostic data productivity hub called Matillion Data Productivity Cloud. Below is a sample scenario for 3 business units within an organization for the data mart layer of the datawarehouse.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. Data ingestion/integration services. Data orchestration tools.
The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency.
Datawarehouses are a critical component of any organization’s technology ecosystem. The next generation of IBM Db2 Warehouse brings a host of new capabilities that add cloud object storage support with advanced caching to deliver 4x faster query performance than previously, while cutting storage costs by 34x 1.
It was my first job as a data analyst. It helped me to become familiar with popular tools such as Excel and SQL and to develop my analytical thinking. The time I spent at Renault helped me realize that data analytics is something I would be interested in pursuing as a full-time career.
As organizations embrace the benefits of data vault, it becomes crucial to ensure optimal performance in the underlying data platform. One such platform that has revolutionized clouddata warehousing is the Snowflake DataCloud. This can make it nearly impossible to “handwrite” these SQL queries.
A prime example of this is automating repetitive code performed in many models or implementing a new feature introduced in your clouddatawarehouse. Scenarios Now, we need to build the SQL statements. In this case, we have to create it before loading the data. Param SQL : will be executed to create the table.
To date, the company’s data warehousing solutions are largely built from the same template used in 1979. In short, they are still the model of multiple processors and massive disk storage with datawarehouse software on the top layer managing it all. Oh, and let’s not forget those cost savings too!
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
“ Vector Databases are completely different from your clouddatawarehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. This process is repeated until the entire text is divided into coherent segments.
Why You Should Consider Migrating from Netezza to Snowflake With Netezza, IBM was one of the first companies to provide a data warehousing solution to allow organizations to analyze and manage large amounts of data. However, as technology has evolved, the need for more advanced, agile data warehousing solutions has become apparent.
It is supported by querying, governance, and open data formats to access and share data across the hybrid cloud. Through workload optimization across multiple query engines and storage tiers, organizations can reduce datawarehouse costs by up to 50 percent.
It comes with a rather lightweight intellisense, and highlights for both SQL and Jinja use. The real power is the ability to run your models and view the outputs, or even have your SQL compiled to verify that your Jinja or SQL compiles into the correct model. Our team of data experts are happy to assist. Reach out today!
Organizations need to ensure that data use adheres to policies (both organizational and regulatory). In an ideal world, you’d get compliance guidance before and as you use the data. Imagine writing a SQL query or using a BI dashboard with flags & warnings on compliance best practice within your natural workflow.
Fivetran is here to simplify that, providing a single platform that can centralize your data in a performant and optimized manner at scale. One particular way Fivetran scales its replication so easily is the recent options for database technologies like DB2 or SQL Server using high volume database agents (or HVA).
Amazon Redshift is a fully managed, fast, secure, and scalable clouddatawarehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a datawarehouse such as Amazon Redshift. This should return the records successfully for further data processing and analysis.
The tool converts the templated configuration into a set of SQL commands that are executed against the target Snowflake environment. Replicate can interact with a wide variety of databases, datawarehouses, and data lakes (on-premise or based in the cloud). It is also a helpful tool for learning a new SQL dialect.
One big issue that contributes to this resistance is that although Snowflake is a great clouddata warehousing platform, Microsoft has a data warehousing tool of its own called Synapse. The June 2021 release of Power BI Desktop introduced Custom SQL queries to Snowflake in DirectQuery mode.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content