This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and data science. CloudData Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? apply(([serverName, rgName, dbName]) => { return `Server=tcp:${serverName}.database.windows.net;initial
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
There are advantages and disadvantages to both ETL and ELT. The post Understanding the ETL vs. ELT Alphabet Soup and When to Use Each appeared first on DATAVERSITY. To understand which method is a better fit, it’s important to understand what it means when one letter comes before the other.
Data management approaches are varied and may be categorised in the following: Clouddata management. The storage and processing of data through a cloud-based system of applications. Master data management. Extraction, Transform, Load (ETL). It is used for managing processes in a datacloud warehouse.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for clouddatabase platforms. Database names, Cloud Region, etc. We should use the Snowflake “SQL Script” component to run the process natively in Snowflake for any resource-intensive data processing.
For existing event sources, listeners are utilized to stream writes directly from database logs or similar data stores. By treating every data point as a streaming event, the Kappa architecture enables the ability to near-realtime analytics and observe the state of all data in the organization at any given point.
With ELT, we first extract data from source systems, then load the raw data directly into the data warehouse before finally applying transformations natively within the data warehouse. This is unlike the more traditional ETL method, where data is transformed before loading into the data warehouse.
Cloud-based business intelligence (BI): Cloud-based BI tools enable organizations to access and analyze data from cloud-based sources and on-premises databases. These tools offer the flexibility of accessing insights from anywhere, and they often integrate with other cloud analytics solutions.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
As organizations embrace the benefits of data vault, it becomes crucial to ensure optimal performance in the underlying data platform. One such platform that has revolutionized clouddata warehousing is the Snowflake DataCloud. However, joining tables using a hash key can take longer than a sequential key.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means. How Did the Modern Data Stack Get Started? A Note on the Shift from ETL to ELT.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. For a longer overview, along with insights and best practices, please feel free to jump back to the previous blog.
How can an organization enable flexible digital modernization that brings together information from multiple data sources, while still maintaining trust in the integrity of that data? To speed analytics, data scientists implemented pre-processing functions to aggregate, sort, and manage the most important elements of the data.
Using clouddata services can be nerve-wracking for some companies. Yes, it’s cheaper, faster, and more efficient than keeping your data on-premises, but you’re at the provider’s mercy regarding your available data. Things like this always happen, taking many hours and expenses to get right.
In recent years, data engineering teams working with the Snowflake DataCloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Having been built completely for and in the cloud, the Snowflake DataCloud has become an industry leader in clouddata platforms.
As companies strive to leverage AI/ML, location intelligence, and cloud analytics into their portfolio of tools, siloed mainframe data often stands in the way of forward momentum. CDC replicates data in real time by ingesting database logs, parsing the information they contain, and initiating parallel changes in a target system.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. It will automatically scale queries to handle any size data set, so you can focus on analyzing your data.
With Snowflake, organizations can be data consumers, data providers, or both. Complete SQL Database No need to learn new tools as Snowflake supports the tools millions of business users already know how to use today.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is the ability to create alerts based on data in Snowflake. How does CRON work for scheduling alerts?
Through workload optimization across multiple query engines and storage tiers, organizations can reduce data warehouse costs by up to 50 percent. 1 Watsonx.data offers built-in governance and automation to get to trusted insights within minutes, and integrations with existing databases and tools to simplify setup and user experience.
The Snowflake DataCloud is a leading clouddata platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake.
Unlike traditional BI tools, its user-friendly interface ensures that users of all technical levels can seamlessly interact with data. The platform’s integration with clouddata warehouses like Snowflake AI DataCloud , Google BigQuery, and Amazon Redshift makes it a vital tool for organizations harnessing big data.
As the latest iteration in this pursuit of high-quality data sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, data quality , and ETL/ELT. And it injects mature process control techniques from the world of traditional engineering.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Modern low-code/no-code ETL tools allow data engineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Snowflake’s DataCloud has emerged as a leader in clouddata warehousing. As a fundamental piece of the modern data stack , Snowflake is helping thousands of businesses store, transform, and derive insights from their data easier, faster, and more efficiently than ever before.
Hashed PKs were introduced as a means of eliminating the bottleneck encountered by most database sequence generators, making this DV pattern ideal for customers prioritizing data loading performance and using data warehouse automation tools. By combining the Snowflake DataCloud with a Data Vault 2.0
With the birth of clouddata warehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
Reduced User Experience : As previously mentioned, data silos can lead to problems down the road. Applications may draw data from different databases, sometimes in different formats. Keeping data siloed also makes adopting new technologies more difficult.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















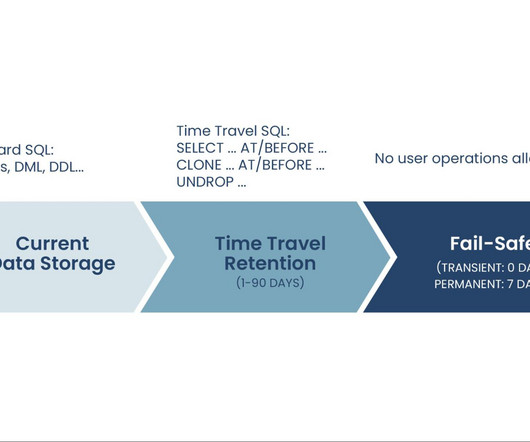
























Let's personalize your content