This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Amazon’s Redshift Database is a cloud-based large data warehousing solution. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system.
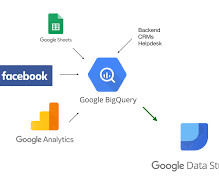
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-clouddata warehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
A provisioned or serverless Amazon Redshift data warehouse. Basic knowledge of a SQL query editor. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2. Database name : Enter dev. Database user : Enter awsuser. A SageMaker domain.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? apply(([serverName, rgName, dbName]) => { return `Server=tcp:${serverName}.database.windows.net;initial
Kinetica, the database for time & space, announced a totally free version of Kinetica Cloud where anyone can sign-up instantly without a credit card to experience Kinetica’s generative AI capabilities to analyze real-time data.
In addition to Business Intelligence (BI), Process Mining is no longer a new phenomenon, but almost all larger companies are conducting this data-driven process analysis in their organization. The Event Log Data Model for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure Data Lake. Here they are in my order of importance (based upon my opinion).
However, the value of the data you gather is determined by the quality of the insights you derive from it and how successfully you can incorporate these insights into your company’s infrastructure and future business strategies. This helps companies extract the maximum amount of value from their data sets. 2 – Leverage caching.
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Thus, was born a single database and the relational model for transactions and business intelligence. ” His paper and research went on to inspire Donald D.
Data warehouse, also known as a decision support database, refers to a central repository, which holds information derived from one or more data sources, such as transactional systems and relational databases. The data collected in the system may in the form of unstructured, semi-structured, or structured data.
“ Vector Databases are completely different from your clouddata warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. Are you interested in exploring Snowflake as a vector database?
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Recognizing these specific needs, Fivetran has developed a range of connectors, including dedicated applications, databases, files, and events, which can accommodate the diverse formats used by healthcare systems. Addressing these needs may pose challenges that lead to the implementation of custom solutions rather than a uniform approach.
Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions. Learn computer vision using Python in the cloudData Science Statistical Knowledge : Expertise in statistics to analyze and interpret data accurately.
Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions. Learn computer vision using Python in the cloudData Science Statistical Knowledge : Expertise in statistics to analyze and interpret data accurately.
As a result, users boost pipeline performance while ensuring data security and controls. Hybrid clouddata integration Traditional data integration solutions often face latency and scalability challenges when integrating data across hybrid cloud environments.
Services such as the Snowflake DataCloud can house massive amounts of data and allows users to write queries to rapidly transform raw data into reports and further analyses. For somebody who cannot access their database directly or who lacks expert-level skills in SQL, this provides a significant advantage.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
Data Bank runs just like any other digital bank — but it isn’t only for banking activities, they also have the world’s most secure distributed data storage platform! Customers are allocated clouddata storage limits which are directly linked to how much money they have in their accounts. BECOME a WRITER at MLearning.ai
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
Organizations that move forward with implementing strategies for sustainability capitalize on the operational, cost, resource utilization and competitive benefits of solution features like load-based “just in time” scaling, offerings of managed services like Azure, clouddata center proximity and database right-sizing through caching.
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : CloudData warehouses like Snowflake and Big Query already have a default time travel feature.
A prime example of this is automating repetitive code performed in many models or implementing a new feature introduced in your clouddata warehouse. It depends on the database we will use for our project. The adapter’s name ( snowflake ) must be passed in for any specific type of database, such as Snowflake.
In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms. We will specifically focus on how to enable it for the Snowflake cloud platform, taking into consideration the account and schema-level object hierarchy.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. Designed to cheaply and efficiently process large quantities of data.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for clouddatabase platforms. Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP. Database names, Cloud Region, etc.
It allows users to store Db2 column-organized tables in object storage in Db2’s highly optimized native page format, all while maintaining full SQL compatibility and capability. TB, with 60% allocated to the on-disk cache (180 GB per database partition, or 2.16TB total). Try Db2 Warehouse for free today 1.
Many of these sources include modern data stack tools, including Fivetran and dbt for ELT, Snowflake for clouddata warehousing , and Databricks for lakehouse. However, in order to disseminate intelligence about data, we need to meet users where they are, in the tools where they work.
However, if there’s one thing we’ve learned from years of successful clouddata implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. This includes users, roles, schemas, databases, and warehouses.
The Snowflake DataCloud is a powerful and industry-leading clouddata platform. The ODBC setup will require the following credential information: Account Name (Server), Database, Schema, Warehouse, and Role. In Designer Desktop, you can use either the Data Input or Connect In-DB tool to connect to Snowflake.
Data Warehousing ist seit den 1980er Jahren die wichtigste Lösung für die Speicherung und Verarbeitung von Daten für Business Intelligence und Analysen. Mit der zunehmenden Datenmenge und -vielfalt wurde die Verwaltung von Data Warehouses jedoch immer schwieriger und teurer.
There are many frameworks for testing software, but the right way to test the data and SQL scripts that change data are less obvious. This is because databases and the data therein are constantly changing. Consider the scenario where you create a view in the database using your Development (DEV) environment.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. It will automatically scale queries to handle any size data set, so you can focus on analyzing your data.
We look forward to continued collaboration that will open up new opportunities for users to take their analytics to the next level in the cloud,” said Gerrit Kazmaier, Vice President & General Manager for Database, Data Analytics and Looker at Google Cloud. Your data in the cloud.
Creating the databases, schemas, roles, and access grants that comprise a data system information architecture can be time-consuming and error-prone. Luckily phData has created a template-driven Provision Tool that automates onboarding users and projects to Snowflake, allowing your data teams to start producing real value immediately.
Fivetran is an automated data integration platform that offers a convenient solution for businesses to consolidate and sync data from disparate data sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any clouddata platform in the market.
Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] 1] It also offers built-in governance, automation and integrations with an organization’s existing databases and tools to simplify setup and user experience.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content