This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: CloudData Warehouse Service appeared first on Analytics Vidhya. The datasets range in size from a few 100 megabytes to a petabyte. […].
The SDK allows data scientists to use Python to create state-of-the-art features and deploy feature pipelines in minutes – all with just a few lines of code. FeatureByte automatically generates complex, time-aware SQL to perform feature transformations at scale in clouddata platforms such as Databricks and Snowflake.
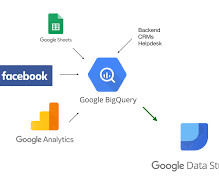
Introduction Google Big Query is a secure, accessible, fully-manage, pay-as-you-go, server-less, multi-clouddata warehouse Platform as a Service (PaaS) service provided by Google Cloud Platform that helps to generate useful insights from big data that will help business stakeholders in effective decision-making.
A provisioned or serverless Amazon Redshift data warehouse. Basic knowledge of a SQL query editor. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2. For this post we’ll use a provisioned Amazon Redshift cluster. A SageMaker domain.
Lots of announcements this week, so without delay, let’s get right to CloudData Science 9. Google Announces CloudSQL for Microsoft SQL Server Google’s CloudSQL now supports SQL Server in addition to PostgreSQL and MySQL Google Opens a new Cloud Region Located in Salt Lake City, Utah, it is named us-west3.
Welcome to CloudData Science 7. Announcements around an exciting new open-source deep learning library, a new data challenge and more. Google has an updated Data Engineering Learning path. Thanks for reading the weekly news, and you can find previous editions on the CloudData Science News page.
Recently introduced as part of I BM Knowledge Catalog on Cloud Pak for Data (CP4D) , automated microsegment creation enables businesses to analyze specific subsets of data dynamically, unlocking patterns that drive precise, actionable decisions. Step 4: Press SelectColumn Select the column you want to base segmentation on.
Sign Up for the CloudData Science Newsletter. Amazon Athena and Aurora add support for ML in SQL Queries You can now invoke Machine Learning models right from your SQL Queries. If you would like to get the CloudData Science News as an email, you can sign up for the CloudData Science Newsletter.
Welcome to the first beta edition of CloudData Science News. This will cover major announcements and news for doing data science in the cloud. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Azure Synapse Analytics This is the future of data warehousing.
By automating the provisioning and management of cloud resources through code, IaC brings a host of advantages to the development and maintenance of Data Warehouse Systems in the cloud. So why using IaC for CloudData Infrastructures? apply(([serverName, rgName, dbName]) => { return `Server=tcp:${serverName}.database.windows.net;initial
Kinetica, the database for time & space, announced a totally free version of Kinetica Cloud where anyone can sign-up instantly without a credit card to experience Kinetica’s generative AI capabilities to analyze real-time data.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered clouddata warehouse, delivering the best price-performance for your analytics workloads.
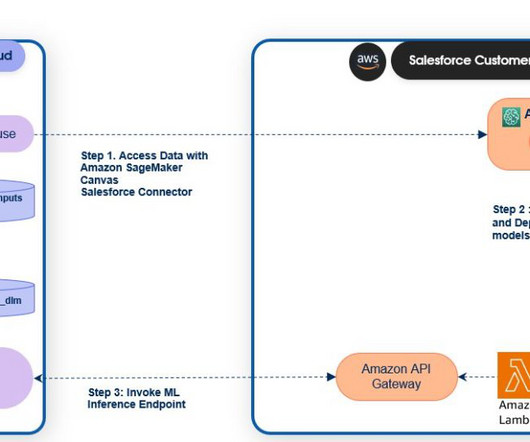
The workflow includes the following steps: Within the SageMaker Canvas interface, the user composes a SQL query to run against the GCP BigQuery data warehouse. Athena returns the queried data from BigQuery to SageMaker Canvas, where you can use it for ML model training and development purposes within the no-code interface.
The data in Amazon Redshift is transactionally consistent and updates are automatically and continuously propagated. Together with price-performance, Amazon Redshift offers capabilities such as serverless architecture, machine learning integration within your data warehouse and secure data sharing across the organization.
This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights. A standout application is the SQL-to-natural language capability, which translates complex SQL queries into plain English and vice versa, bridging the gap between technical and business teams.
Sigma Computing , a cloud-based analytics platform, helps data analysts and business professionals maximize their data with collaborative and scalable analytics. One of Sigma’s key features is its support for custom SQL queries and CSV file uploads.
Microsoft just held one of its largest conferences of the year, and a few major announcements were made which pertain to the clouddata science world. Azure Synapse Analytics can be seen as a merge of Azure SQLData Warehouse and Azure Data Lake. Here they are in my order of importance (based upon my opinion).
In the sales domain, this enables real-time monitoring of live sales activities, offering immediate insights into performance and rapid response to emerging trends or issues. Data Factory: Data Factory enhances the data integration experience by offering support for over 200 native connectors to both on-premises and clouddata sources.
Data can be generated from databases, sensors, social media platforms, APIs, logs, and web scraping. Data can be in structured (like tables in databases), semi-structured (like XML or JSON), or unstructured (like text, audio, and images) form.
Formerly known as Periscope, Sisense is a business intelligence tool ideal for clouddata teams. With this tool, analysts are able to visualize complex data models in Python, SQL, and R. This highly flexible and modern SQL editor comes bundled with an easy-to-use, attractive interface.
For many enterprises, a hybrid clouddata lake is no longer a trend, but becoming reality. With a cloud deployment, enterprises can leverage a “pay as you go” model; reducing the burden of incurring capital costs. Due to these needs, hybrid clouddata lakes emerged as a logical middle ground between the two consumption models.
Snowflake’s cloud-agnosticism, separation of storage and compute resources, and ability to handle semi-structured data have exemplified Snowflake as the best-in-class clouddata warehousing solution. Snowflake supports data sharing and collaboration across organizations without the need for complex data pipelines.
Usually the term refers to the practices, techniques and tools that allow access and delivery through different fields and data structures in an organisation. Data management approaches are varied and may be categorised in the following: Clouddata management. Master data management.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
The division between data lakes and data warehouses is stifling innovation. Nearly three-quarters of the organizations surveyed in the previously mentioned Databricks study split their clouddata landscape into two layers: a data lake and a data warehouse. .
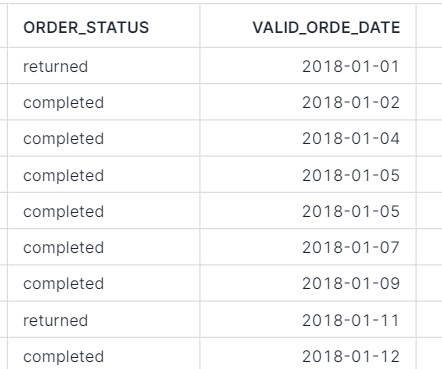
Example Event Log for Process Mining The following example SQL-query is inserting Event-Activities from a SAP ERP System into an existing event log database table. A simple event log is therefore a simple table with the minimum requirement of a process number (case ID), a time stamp and an activity description.
Data Bank runs just like any other digital bank — but it isn’t only for banking activities, they also have the world’s most secure distributed data storage platform! Customers are allocated clouddata storage limits which are directly linked to how much money they have in their accounts. BECOME a WRITER at MLearning.ai
The fact of the matter is Looker will never be able to solve at scale because it must wait for queries to complete on the data warehouse side. This creates a bottleneck as many of the clouddata warehouse solutions are simply too slow to keep up. This should see dashboard load times increase dramatically. Final word.
Codd published his famous paper “ A Relational Model of Data for Large Shared Data Banks.” Boyce to create Structured Query Language (SQL). Developers can leverage features like REST APIs, JSON support and enhanced SQL compatibility to easily build cloud-native applications. Chamberlin and Raymond F.
Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions. Learn computer vision using Python in the cloudData Science Statistical Knowledge : Expertise in statistics to analyze and interpret data accurately.
Algorithms and Data Structures : Deep understanding of algorithms and data structures to develop efficient and effective software solutions. Learn computer vision using Python in the cloudData Science Statistical Knowledge : Expertise in statistics to analyze and interpret data accurately.
Introduction Snowflake is a cloud-based data warehousing platform that enables enterprises to manage vast and complicated information by providing scalable storage and processing capabilities. It is intended to be a fully managed, multi-cloud solution that does not need clients to handle hardware or software.
A prime example of this is automating repetitive code performed in many models or implementing a new feature introduced in your clouddata warehouse. Scenarios Now, we need to build the SQL statements. In this case, we have to create it before loading the data. In our case, we need to set up the temporary table SQL first.
Fivetran enables healthcare organizations to ingest data securely and effectively from a variety of sources into their target destinations, such as Snowflake or other clouddata platforms, for further analytics or curation for sharing data with external providers or customers.
Set up OAuth for Salesforce DataCloud in SageMaker Canvas. Connect to Salesforce DataClouddata using the built-in SageMaker Canvas Salesforce DataCloud connector and import the dataset. Configure the following scopes on your connected app: Manage user data via APIs ( api ).
Amazon Redshift is the most popular clouddata warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. You can use query_string to filter your dataset by SQL and unload it to Amazon S3. If you’re familiar with SageMaker and writing Spark code, option B could be your choice.
The data collected in the system may in the form of unstructured, semi-structured, or structured data. This data is then processed, transformed, and consumed to make it easier for users to access it through SQL clients, spreadsheets and Business Intelligence tools.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of clouddata warehouses and AI/ LLMs has transformed what businesses can do with data. Designed to cheaply and efficiently process large quantities of data.
Additionally, Tableau allows customers using BigQuery ML to easily visualize the results of predictive machine learning models run on data stored in BigQuery. This minimizes the amount of SQL you need to write to create and execute models, as well as analyze the results—making machine learning techniques easier to use.
Services such as the Snowflake DataCloud can house massive amounts of data and allows users to write queries to rapidly transform raw data into reports and further analyses. For somebody who cannot access their database directly or who lacks expert-level skills in SQL, this provides a significant advantage.
A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a clouddata warehouse like Snowflake. Intuitive Workflow Design Workflows should be easy to follow and visually organized, much like clean, well-structured SQL or Python code.
As a result, users boost pipeline performance while ensuring data security and controls. Hybrid clouddata integration Traditional data integration solutions often face latency and scalability challenges when integrating data across hybrid cloud environments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content