This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Hierarchical clustering is one of the most famous clustering techniques used in unsupervised machine learning. K-means and hierarchical clustering are the two most popular and effective clustering algorithms. The post Hierarchical Clustering in Machine Learning appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Clustering The very first clustering algorithm that most people get exposed to is k-Means clustering. Clustering is generally viewed as an unsupervised […]. The post Beginners guide to k-Means Clustering appeared first on Analytics Vidhya.
Welcome to this wide-ranging article on clustering in data science! In this article, we will be discussing what is clustering, why is clustering required, various applications of clustering, a brief about the […]. There’s a lot to unpack so let’s dive straight in.
Overview K-means clustering is a very famous and powerful unsupervised machine learning. The post A Simple Explanation of K-Means Clustering appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction Clustering is an unsupervised machine learning algorithm that groups together similar data points based on criteria like shared attributes. Each cluster has data points that are similar to the other data points in the cluster while as a whole, the cluster is dissimilar to other data points.
The post Adding Explainability to Clustering appeared first on Analytics Vidhya. Explainable AI is no longer just an optional add-on when using ML algorithms for corporate decision making. While there are a lot of techniques that have been developed for supervised algorithms, […].
Introduction Cluster analysis or clustering is an unsupervised machine learning algorithm that. The post A Detailed Introduction to K-means Clustering in Python! This article was published as a part of the Data Science Blogathon. appeared first on Analytics Vidhya.
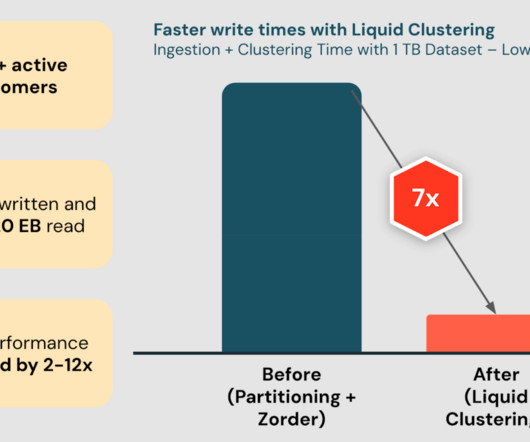
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
Introduction K-means clustering is one of the algorithms which unsupervised machine learning supports hence before moving forward with K-means let’s have background knowledge of the unsupervised learning method. The post Introduction to K-Means Clustering using MLIB appeared first on Analytics Vidhya.
Overview DBSCAN clustering is an underrated yet super useful clustering algorithm for unsupervised learning problems Learn how DBSCAN clustering works, why you should learn. The post How to Master the Popular DBSCAN Clustering Algorithm for Machine Learning appeared first on Analytics Vidhya.
Density-based clustering stands out in the realm of data analysis, offering unique capabilities to identify natural groupings within complex datasets. What is density-based clustering? This method effectively distinguishes dense regions from sparse areas, identifying clusters while also recognizing outliers.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: Clustering is an unsupervised learning method whose job is to. The post Understanding KMeans Clustering for Data Science Beginners appeared first on Analytics Vidhya.
This article is the first in a series of articles looking at the different aspects of k-means clustering, beginning with a discussion on centroid initialization.
Introduction on Video Game Clustering In this article, I am going to cluster some of the popular video games according to their given features. I have done this project while learning about the K-Means Clustering. The post Video Game Clustering Using Python appeared first on Analytics Vidhya.
The post An Approach towards Neural Network based Image Clustering appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction: Hi everyone, recently while participating in a Deep Learning competition, I.
Introduction Clustering is an unsupervised machine learning technique. The post In-depth Intuition of K-Means Clustering Algorithm in Machine Learning appeared first on Analytics Vidhya. ArticleVideos This article was published as a part of the Data Science Blogathon.
The post Understanding K – Means Clustering WIth Customer Segmentation Usecase appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview This article will help us understand the working behind K-means.
The post Introduction to Clustering in Python for Beginners in Data Science appeared first on Analytics Vidhya. Introduction Extracting knowledge from the data has always been an important task, especially when we want to make a decision based on data.
As a result of the efforts outlined in this article, we confirmed that clustering through crowdsourcing is indeed possible and works impressively well.
Clustering is a widely applied method in many domains like customer and image segmentation, image recognition, bioinformatics, and anomaly detection, all to group data into clusters in terms of similarity.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction: Clustering is an unsupervised learning method whose task is to. The post KModes Clustering Algorithm for Categorical data appeared first on Analytics Vidhya.
Fluidstack, an AI cloud platform, announced it is deploying and managing exascale clusters across Iceland and Europe in collaboration with Borealis Data Center, Dell Technologies and NVIDIA. Our mission has.
The post Understanding K-means Clustering in Machine Learning(With Examples) appeared first on Analytics Vidhya. Even though the nature of individual data is straightforward, the sheer amount of data to be analyzed makes processing difficult for even computers. To […].
Overview Clustering is an unsupervised machine learning algorithm that basically groups similar things together. Recommendation Engines is a fundamental application of clustering. We will build a Collaborative filtering Book recommendation system and compare flat vs hierarchical clustering; which works better?
Were excited to announce the Public Preview of Automatic Liquid Clustering, powered by Predictive Optimization. This feature automatically applies and updates Liquid Clustering columns on.
This tutorial provides hands-on experience with the key concepts and implementation of K-Means clustering, a popular unsupervised learning algorithm, for customer segmentation and targeted advertising applications.
In this guide to hierarchical clustering, learn how agglomerative and divisive clustering algorithms work. Also build a hierarchical clustering model in Python using Scipy.
In a previous tutorial, we have explored the use of the k-means clustering algorithm as an unsupervised machine learning technique that seeks to group similar data into distinct clusters, to uncover patterns in the data.
The post Real-World Machine Learning Case Study: Clustering Transactions Based on Text Descriptions appeared first on Analytics Vidhya. Introduction We are living in the era of digital technologies. When was the last time you walked into a shop that didn’t have a.
Introduction K-means clustering is an unsupervised algorithm. In an unsupervised algorithm, The post K-Mean: Getting The Optimal Number Of Clusters appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon.
Clustering algorithms play a vital role in the landscape of machine learning, providing powerful techniques for grouping various data points based on their intrinsic characteristics. What are clustering algorithms? Key criteria include: The number of clusters data points can belong to.
The post Using Docker to Create a Cassandra Cluster appeared first on Analytics Vidhya. It is seen that RDBMS(Relational DataBase Management System) does not offer an optimal solution for handling huge volumes […].
This quiz series features 10 thought-provoking questions on Clustering Algorithms in Machine Learning. Thanks for […] The post Quiz of the Day (Clustering) #5 appeared first on Analytics Vidhya. Whether you’re an expert or a curious learner, our quizzes cater to all levels. Let’s Begin!
The post Beginner’s Guide to Cluster Analysis of Stock Returns appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction When it comes to investing it is difficult to find.
The post Colour Quantization Using K-Means Clustering and OpenCV appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Image by author This article can appear as a particularly impressive.
The answer lies in clustering, a powerful technique in machine learning and data analysis. Clustering algorithms allow us to group data points based on their similarities, aiding in tasks ranging from customer segmentation to image analysis.
We are excited to announce that cluster policies are now generally available. Why Databricks cluster policies? Databricks cluster policies enable administrators to: limit.
This is where the organization part comes in— by categorizing the brands as a whole or taking a more […] The post Classification vs. Clustering- Which One is Right for Your Data? Would you be able to find the desired brand or product easily? Definitely not. appeared first on Analytics Vidhya.
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.
Our friends over at Silicon Mechanics put together a guide for the Triton Big Data Cluster™ reference architecture that addresses many challenges and can be the big data analytics and DL training solution blueprint many organizations need to start their big data infrastructure journey.
We are thrilled to announce great enhancements to onboard more workloads to Unity Catalog clusters in shared access mode, Databricks' highly efficient, secure.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









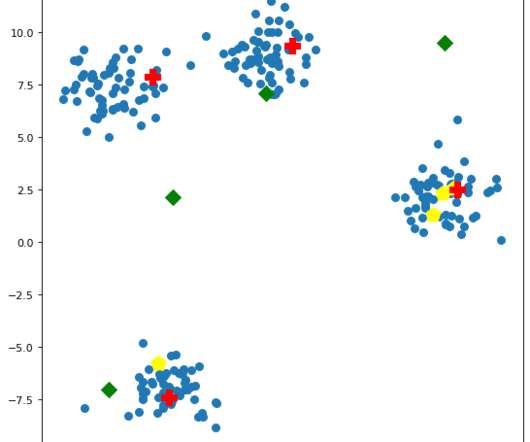

























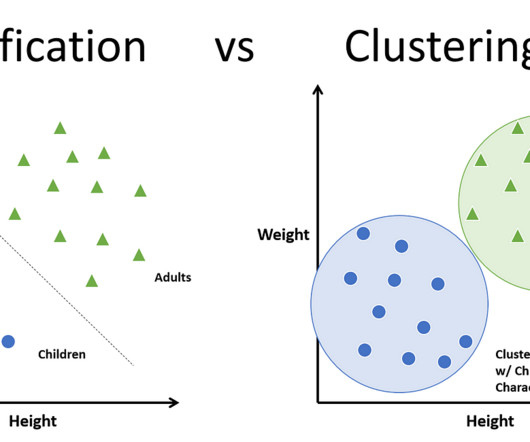









Let's personalize your content