This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, customizing these larger models requires access to the latest and accelerated compute resources. In this post, we demonstrate how you can address this requirement by using Amazon SageMaker HyperPod training plans , which can bring down your training cluster procurement wait time. For Target , select HyperPod cluster.
Del Complex hopes floating its computerclusters in the middle of the ocean will allow it a level of autonomy unlikely to be found on land. Government …
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Its mounted at /fsx on the head and compute nodes. Scheduler : SLURM is used as the job scheduler for the cluster.
Introduction Voronoi diagrams, named after the Russian mathematician Georgy Voronoy, are fascinating geometric structures with applications in various fields such as computerscience, geography, biology, and urban planning.
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
It is important to consider the massive amount of compute often required to train these models. When using computeclusters of massive size, a single failure can often throw a training job off course and may require multiple hours of discovery and remediation from customers.
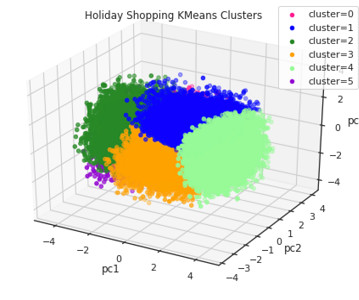
In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise. The purpose is to improve accuracy by either training a global model that contains the cluster configuration or have local models specific to each cluster.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
One of the simplest and most popular methods for creating audience segments is through K-means clustering, which uses a simple algorithm to group consumers based on their similarities in areas such as actions, demographics, attitudes, etc. In this tutorial, we will work with a data set of users on Foursquare’s U.S.
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
As cluster sizes grow, the likelihood of failure increases due to the number of hardware components involved. Larger clusters, more failures, smaller MTBF As cluster size increases, the entropy of the system increases, resulting in a lower MTBF. It implies that if a single instance fails, it stops the entire job.
The study found that cation vacancy defects in wustite tend to aggregate, forming stable cluster structures. It also elucidated the formation mechanisms of interstitial iron atoms and typical defect clusters in wustite, establishing the formation preference for Koch–Cohen defect clusters.
To maximize coherence by separating true and false statements into different clusters. The problem of finding the most coherent partition in a graph turns out to be mathematically equivalent to MAX-CUT , a well-known computational challenge. The researchers’ approach takes inspiration from both psychology and computerscience.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. In response, SageMaker spins up training jobs with the requested number and type of compute instances. 24xlarge compute instance.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
Machine Learning is a subset of Artificial Intelligence and ComputerScience that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
Artificial intelligence infrastructure provider Nebius Group NV today announced the launch of its first graphics processing unit clusters in the U.S. …
As the camera moves out, the cubes form clusters of similar colors. A camera moves through a cloud of multi-colored cubes, each representing an email message. Three passing cubes are labeled “k *@enron.com”, “m @enron.com” and “j **@enron.com.” By Jeremy White Dec. 22, 2023 Last month, I …
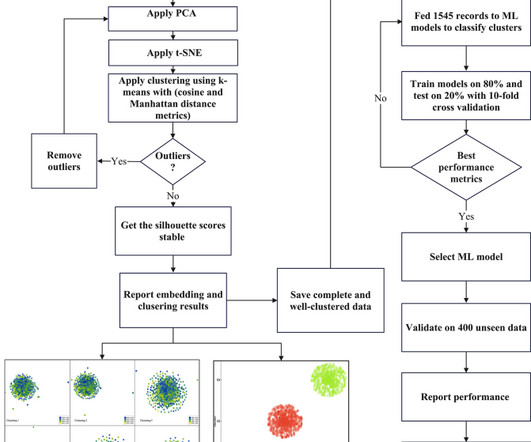
However, these studies used small datasets, had overfitting problems, lacked generalizability, or used complex algorithms that may require additional computational resources. In this study, we collected and analyzed center-based data and used a recursive embedding and clustering technique to reduce their dimensionality.
Wes Ramage was born with a condition called optic nerve hypoplasia, an underdevelopment of the clusters of cells that relay signals from the retina to the brain. He can see objects, but no details. His family moved around a lot throughout Southern Ontario. As a kid with extremely limited vision, he …
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. Alternatively, you can also use the AWS CloudFormation template provided in the Own Account workshop and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.
Andrew Wilson (Associate Professor of ComputerScience and Data Science) “ A Performance-Driven Benchmark for Feature Selection in Tabular Deep Learning ” by Valeriia Cherepanova, Roman Levin, Gowthami Somepalli, Jonas Geiping, C.
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Figure 2 : Amazon OpenSearch Service for Vector Search: Demo Key Features of AWS OpenSearch Scalability: Easily scale clusters up or down based on workload demands.
A right-sized cluster will keep this compressed index in memory. Dylan holds a BSc and MEng degree in ComputerScience from Cornell University. This conversion results in a 32 times compression rate, enabling the engine to build an index that is 97% smaller than one composed of full-precision vectors.
With technological developments occurring rapidly within the world, ComputerScience and Data Science are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in Data Science job roles, transitioning your career from ComputerScience to Data Science can be quite interesting.
This work proposes a robust solution for identifying and classifying a wide spectrum of materials through an iterative technique, called symmetry-based clustering (SBC). Instead, it identifies clusters in atomistic systems by automatically recognizing common unit cells.
For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training. We also used AWS ParallelCluster to manage cluster orchestration. Before moving to industry, Tahir earned an M.S.
Their architecture combines high-performance FSx for Lustre storage with NVIDIA GPU clusters for training, and NVIDIA Triton Inference Server handles production deployment. He holds a degree in ComputerScience from MIT and an Executive MBA from the University of Washington.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
One resembles the kind of pickup soccer game, usually with very young kids or drunk adults, where every player clusters in a … Here's why. There are, roughly speaking, two Silicon Valleys.
Unsupervised learning: Focuses on discovering hidden patterns in unlabelled data, often used for clustering and association tasks. Reinforcement learning: Leverages reward-based systems to train models through trial and error, optimizing decision-making over time.
ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
Set up the CloudWatch Observability EKS add-on Refer to Install the Amazon CloudWatch Observability EKS add-on for instructions to create the amazon-cloudwatch-observability add-on in your EKS cluster. The Container Insights dashboard also shows cluster status and alarms. os operator: In values: - linux - key: node.kubernetes.io/instance-type
Here, we present DeepCellMap, a deep-learning-assisted tool that integrates multi-scale image processing with advanced spatial and clustering statistics. DeepCellMap, a deep-learning tool, maps microglial organisation in the developing brain, revealing their spatial diversity, clustering patterns, and associations with blood vessels.
However, generative AI requires powerful, scalable, and resilient infrastructures that optimize large-scale model training, providing rapid iteration and efficient compute utilization with purpose-built infrastructure and automated cluster management. What is SageMaker HyperPod? This post shows how this can be done in discrete steps.
Machine learning is a field of computerscience that uses statistical techniques to build models from data. Unsupervised learning models, like clustering and dimensionality reduction, aid in uncovering hidden structures within data. There are many different types of models that can be used in data science.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content