This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A right-sized cluster will keep this compressed index in memory. Dylan holds a BSc and MEng degree in ComputerScience from Cornell University. This conversion results in a 32 times compression rate, enabling the engine to build an index that is 97% smaller than one composed of full-precision vectors.
In this tutorial, well explore how OpenSearch performs k-NN (k-NearestNeighbor) search on embeddings. Each word or sentence is mapped to a high-dimensional vector space, where similar meanings cluster together. OpenSearch uses k-NearestNeighbors (k-NN) search to find the most similar embeddings in the dataset.
We shall look at various types of machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R.,
According to IBM, machine learning is a subfield of computerscience and artificial intelligence (AI) that focuses on using data and algorithms to simulate human learning processes while progressively increasing their accuracy.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others.
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Figure 2 : Amazon OpenSearch Service for Vector Search: Demo Key Features of AWS OpenSearch Scalability: Easily scale clusters up or down based on workload demands.
This technique expresses a text item as a feature vector, which can be used to compute cosine similarity with other item feature vectors. Figure 7: TF-IDF calculation (source: Towards Data Science ). Figure 8: K-nearestneighbor algorithm (source: Towards Data Science ). Several clustering algorithms (e.g.,
e "discovery.type=single-node" : Runs OpenSearch as a single-node cluster (since were not setting up a distributed system locally). You should see details about cluster health, the number of nodes, and the OpenSearch version. You should see details about cluster health, the number of nodes, and the OpenSearch version.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. As an example, in the following figure, we separate Cover 3 Zone (green cluster on the left) and Cover 1 Man (blue cluster in the middle).
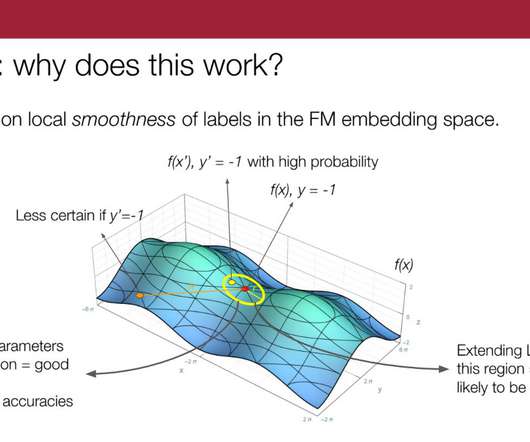
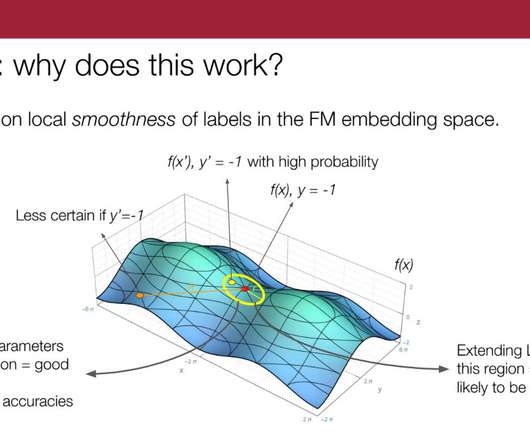
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
I am a PhD student in the computerscience department at Stanford, advised by Chris Ré working on some broad themes of understanding data-centric AI, weak supervision and theoretical machine learning. So, we propose to do this sort of K-nearest-neighbors-type extension per source in the embedding space.
Complete the following steps: On the OpenSearch Service console, choose Dashboard under Managed clusters in the navigation pane. In most cases, you will use an OpenSearch Service vector database as a knowledge base, performing a k-nearestneighbor (k-NN) search to incorporate semantic information in the retrieval with vector embeddings.
Read the full article here — [link] For final-year students pursuing a degree in computerscience or related disciplines, engaging in machine learning projects can be an excellent way to consolidate theoretical knowledge, gain practical experience, and showcase their skills to potential employers. Working Video of our App [link] 20.
Artificial Intelligence (AI): A branch of computerscience focused on creating systems that can perform tasks typically requiring human intelligence. Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content