This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks. They are able to learn long-range dependencies between words, which is essential for understanding the nuances of human language. They are typically trained on clusters of computers or even on cloud computing platforms.
Machine Learning is a subset of Artificial Intelligence and ComputerScience that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
Amazon SageMaker HyperPod offers an effective solution for provisioning resilient clusters to run ML workloads and develop state-of-the-art models. He specializes in solving complex computer vision and naturallanguageprocessing challenges and advancing the practical use of generative AI in business.
For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training. We also used AWS ParallelCluster to manage cluster orchestration. Before moving to industry, Tahir earned an M.S.
With technological developments occurring rapidly within the world, ComputerScience and Data Science are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in Data Science job roles, transitioning your career from ComputerScience to Data Science can be quite interesting.
Naturallanguageprocessing (NLP) has been growing in awareness over the last few years, and with the popularity of ChatGPT and GPT-3 in 2022, NLP is now on the top of peoples’ minds when it comes to AI. Computerscience, math, statistics, programming, and software development are all skills required in NLP projects.
ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
Professional certificate for computerscience for AI by HARVARD UNIVERSITY Professional certificate for computerscience for AI is a 5-month AI course that is inclusive of self-paced videos for participants; who are beginners or possess intermediate-level understanding of artificial intelligence.
The applications of graph classification are numerous, and they range from determining whether a protein is an enzyme or not in bioinformatics to categorizing documents in naturallanguageprocessing (NLP) or social network analysis, among other things. How do Graph Neural Networks work?
The Bay Area Chapter of Women in Big Data (WiBD) hosted its second successful episode on the NLP (NaturalLanguageProcessing), Tools, Technologies and Career opportunities. Currently based in Germany, she possesses extensive experience in developing data-intensive applications leveraging NLP, data science, and data analytics.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. He studied computerscience at UW Seattle.
With advances in machine learning, deep learning, and naturallanguageprocessing, the possibilities of what we can create with AI are limitless. However, the process of creating AI can seem daunting to those who are unfamiliar with the technicalities involved. What is required to build an AI system?
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. It then replaces any faulty instances, if necessary, to make sure the training script starts running on a healthy cluster of instances.
Gözde Gül Şahin | Assistant Professor, KUIS AI Fellow | KOC University Fraud Detection with Machine Learning: Laura Mitchell | Senior Data Science Manager | MoonPay Deep Learning and Comparisons between Large Language Models: Hossam Amer, PhD | Applied Scientist | Microsoft Multimodal Video Representations and Their Extension to Visual Language Navigation: (..)
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Deep Learning has been used to achieve state-of-the-art results in a variety of tasks, including image recognition, NaturalLanguageProcessing, and speech recognition. NaturalLanguageProcessing (NLP) This is a field of computerscience that deals with the interaction between computers and human language.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately? But exactly what is NLP , and how can it facilitate legal discovery?
or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 He also boasts several years of experience with NaturalLanguageProcessing (NLP). bge-small-en-v1.5 What motivated you to compete in this challenge?
Here are a few courses you can check out — AI for Medicine Specialization NaturalLanguageProcessing Specialization Generative Adversarial Networks (GANs) Specialization Educational Background A Bachelor’s degree in a quantitative field like computerscience, mathematics, statistics, or engineering is often the minimum requirement.
These computerscience terms are often used interchangeably, but what differences make each a unique technology? Naturallanguageprocessing (NLP) and computer vision, which let companies automate tasks and underpin chatbots and virtual assistants such as Siri and Alexa, are examples of ANI.
Model invocation We use Anthropics Claude 3 Sonnet model for the naturallanguageprocessing task. This LLM model has a context window of 200,000 tokens, enabling it to manage different languages and retrieve highly accurate answers. temperature This parameter controls the randomness of the language models output.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computerscience, algorithms, and soon. Theyre looking for people who know all related skills, and have studied computerscience and software engineering.
She is a technologist with a PhD in ComputerScience, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. This post proposes Auto-CoT, which samples questions with diversity and generates reasoning chains to construct the demonstrations.
As an example, in the following figure, we separate Cover 3 Zone (green cluster on the left) and Cover 1 Man (blue cluster in the middle). We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. Outside of work, he enjoys soccer and video games.
These embeddings are useful for various naturallanguageprocessing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. Sentence transformers are powerful deep learning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning.
Christopher earned his Bachelor of Science in ComputerScience from Northeastern Illinois University. Sam has a Bachelor of Science in ComputerScience and a Bachelor of Science in Mathematics from the University of Texas at Austin. For pricing information, visit Amazon SageMaker Pricing.
time series or naturallanguageprocessing tasks). Feature Learning Autoencoders can learn meaningful features from input data, which can be used for downstream machine learning tasks like classification, clustering, or regression. Or requires a degree in computerscience? That’s not the case.
PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. In FSI, non-time series workloads are also underpinned by algorithms that can be parallelized.
The 8-billion-parameter model integrates grouped-query attention (GQA) for improved processing of longer data sequences, enhancing real-world application performance. Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2.
Tech companies, they might focus on developing recommendation systems, fraud detection algorithms, or NaturalLanguageProcessing tools. Most professionals in this field start with a bachelor’s degree in computerscience, Data Science, mathematics, or a related discipline. Platforms like Pickl.AI
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. LLMs like ChatGPT are trained on massive amounts of text data, allowing them to recognize patterns and statistical relationships within language.
Here are the key steps to embark on the path towards becoming an AI Architect: Acquire a Strong Foundation Start by building a solid foundation in computerscience, mathematics, and statistics. Explore topics such as regression, classification, clustering, neural networks, and naturallanguageprocessing.
For example, supporting equitable student persistence in computing research through our ComputerScience Research Mentorship Program , where Googlers have mentored over one thousand students since 2018 — 86% of whom identify as part of a historically marginalized group.
It combines various techniques from statistics, mathematics, computerscience, and domain expertise to interpret complex data sets. AI encompasses various subfields, including Machine Learning (ML), NaturalLanguageProcessing (NLP), robotics, and computer vision.
Includes statistical naturallanguageprocessing techniques. Each concept is supported by algorithms, mathematical models, and case studies, making it ideal for readers with a basic understanding of mathematics or computerscience. Key Features: Explains AI algorithms like clustering and regression.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
By translating responses to high-dimensional vector embeddings, clustering algorithms can group the data into discrete sets of documents that share a semantic similarity. LLMs are trained on much larger datasets, which allows them to contain richer information about how words are typically used together.
Artificial Intelligence (AI): A branch of computerscience focused on creating systems that can perform tasks typically requiring human intelligence. Clustering: An unsupervised Machine Learning technique that groups similar data points based on their inherent similarities.
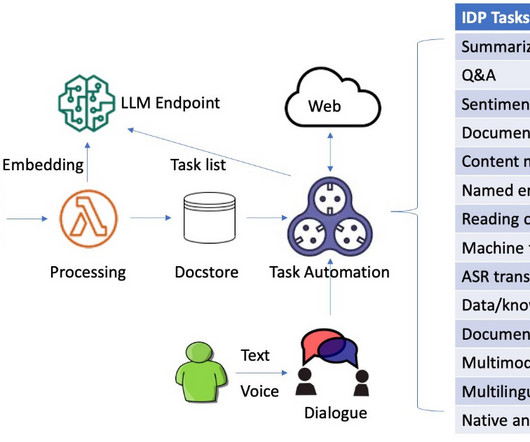
Naturallanguageprocessing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. As an alternative, you can use FAISS , an open-source vector clustering solution for storing vectors. However, despite these advances, there are still challenges to overcome.
A number of breakthroughs are enabling this progress, and here are a few key ones: Compute and storage - The increased availability of cloud compute and storage has made it easier and cheaper to get the compute resources organizations need. Deep learning - It is hard to overstate how deep learning has transformed data science.
Deep learning became the new focus, first led by the advance in computer vision, then followed by naturallanguageprocessing. Training a tens- or hundreds-billion parameter model, using close to a terabyte worth of data, pretty much requires a dedicated supercomputer scale cluster for weeks or months.
Large language models (LLMs) with billions of parameters are currently at the forefront of naturallanguageprocessing (NLP). These models are shaking up the field with their incredible abilities to generate text, analyze sentiment, translate languages, and much more.
Understanding Data Science Data Science is a multidisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. It combines principles from statistics, mathematics, computerscience, and domain-specific knowledge to analyse and interpret complex data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content