This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Discretization is a fundamental preprocessing technique in dataanalysis and machine learning, bridging the gap between continuous data and methods designed for discrete inputs.
Density-based clustering stands out in the realm of dataanalysis, offering unique capabilities to identify natural groupings within complex datasets. What is density-based clustering? This method effectively distinguishes dense regions from sparse areas, identifying clusters while also recognizing outliers.
Introduction Have you ever wondered how vast volumes of data can be untangled, revealing hidden patterns and insights? The answer lies in clustering, a powerful technique in machine learning and dataanalysis.
Get ahead in dataanalysis with our summary of the top 7 must-know statistical techniques. They are also used in machine learning, such as support vector machines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
Summary: Hierarchical clustering in machine learning organizes data into nested clusters without predefining cluster numbers. This method uses distance metrics and linkage criteria to build dendrograms, revealing data structure. Dendrograms provide intuitive visualizations of cluster relationships and hierarchy.
To address this challenge, businesses need to use advanced dataanalysis methods. These methods can help businesses to make sense of their data and to identify trends and patterns that would otherwise be invisible. In recent years, there has been a growing interest in the use of artificial intelligence (AI) for dataanalysis.
If you are a novice in the field of dataanalysis or seeking to enhance your proficiency, a meticulously devised dataanalysis roadmap can serve as an invaluable tool for commencing your journey. Are Data Analysts in Demand in 2023? The world is generating more data than ever before. Be flexible.
That’s akin to the experience of sifting through today’s digital news landscape, except instead of a magical test, we have the power of dataanalysis to help us find the news that matters most to us.
Familiarize yourself with essential data science libraries Once you have a good grasp of Python programming, start with essential data science libraries like NumPy, Pandas, and Matplotlib. Work on projects Apply your knowledge by working on real-world data science projects.
Researchers, data scientists, and machine learning practitioners alike have embraced t-SNE for its effectiveness in transforming extensive datasets into visual representations, enabling a clearer understanding of relationships, clusters, and patterns within the data.
Read a comprehensive SQL guide for dataanalysis; Learn how to choose the right clustering algorithm for your data; Find out how to create a viral DataViz using the data from Data Science Skills poll; Enroll in any of 10 Free Top Notch Natural Language Processing Courses; and more.
ArticleVideo Book Introduction In recent years, data science has become omnipresent in our daily lives, causing many dataanalysis tools to sprout and evolve. The post A Friendly Introduction to KNIME Analytics Platform appeared first on Analytics Vidhya.
Text Analysis: Feature extraction might involve extracting keywords, sentiment scores, or topic information from text data for tasks like sentiment analysis or document classification. Sensor DataAnalysis: Extracting relevant features from sensor data (e.g., shirt, pants). shirt, pants).
It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays. The package is particularly useful for performing mathematical operations on large datasets and is widely used in machine learning, dataanalysis, and scientific computing.
The embedding projector is a powerful visualization tool that helps data scientists and researchers understand complex, high-dimensional data often encountered in machine learning (ML) and natural language processing (NLP). By revealing these clusters, the tool provides important insights that can inform model refinement processes.
These are important for efficient data organization, security, and control. Rules are put in place by databases to ensure data integrity and minimize redundancy. Moreover, organized storage of data facilitates dataanalysis, enabling retrieval of useful insights and data patterns.
Methods such as field surveys and manual satellite dataanalysis are not only time-consuming, but also require significant resources and domain expertise. This often leads to delays in data collection and analysis, making it difficult to track and respond swiftly to environmental changes. format("/".join(tile_prefix),
Cluster Sampling: The population is divided into clusters, and a random sample of clusters is selected, with all members in selected clusters included. Systematic Sampling: Selecting every “kth” element from a population list, using a systematic approach to create the sample.
Common use cases for parallel file systems Parallel file systems find applications across various industry sectors, enhancing capabilities in data-intensive environments. By industry sector National laboratories: Focus on scientific research applications requiring extensive dataanalysis.
Merging clustering and classification Clustering techniques like K-means are instrumental in semi-supervised learning, facilitating the grouping of unlabeled data. K-means works by partitioning data into a number of clusters based on feature similarity.
Choosing the Right Clustering Algorithm for your Dataset; DeepMind Has Quietly Open Sourced Three New Impressive Reinforcement Learning Frameworks; A European Approach to Masters Degrees in Data Science; The Future of Analytics and Data Science. Also: How AI will transform healthcare (and can it fix the US healthcare system?);
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. The data mining process The data mining process is structured into four primary stages: data gathering, data preparation, data mining, and dataanalysis and interpretation.
The unsupervised ML algorithms are used to: Find groups or clusters; Perform density estimation; Reduce dimensionality. Overall, unsupervised algorithms get to the point of unspecified data bits. In this regard, unsupervised learning falls into two groups of algorithms – clustering and dimensionality reduction. Source ].
In a world where data is rapidly generated and accumulated, the ability to distill important features from a vast array of variables can significantly enhance the efficiency and effectiveness of dataanalysis and machine learning models. What is dimensionality reduction?
Summary: The Gaussian Mixture Model (GMM) is a flexible probabilistic model that represents data as a mixture of multiple Gaussian distributions. It excels in soft clustering, handling overlapping clusters, and modelling diverse cluster shapes. EM algorithm iteratively optimizes GMM parameters for best data fit.
– An effective tool in clustering and classification tasks, enhancing the performance of group analysis. Comparison of distributions: It helps identify variations between expected theoretical distributions and the actual data collected, letting researchers understand their data better.
While powerful, these experiments are expensive and time-consuming, requiring thousands of cells and intricate dataanalysis. Gene set enrichment : Identify clusters of genes that behave similarly under perturbations and describe their common function.
This distribution demonstrates how data points tend to cluster around a central mean, with equal probabilities existing for values above and below that mean. Normal distribution, often referred to as Gaussian distribution , is a continuous probability distribution characterized by its symmetrical bell-shaped curve.
Summary: Hierarchical clustering categorises data by similarity into hierarchical structures, aiding in pattern recognition and anomaly detection across various fields. It uses dendrograms to visually represent data relationships, offering intuitive insights despite challenges like scalability and sensitivity to outliers.
Historical context of customer segmentation Historically, customer segmentation relied on manual efforts with limited dataanalysis capabilities. Over time, advancements in Machine learning have rendered these processes more sophisticated, allowing for rapid analysis and a deeper understanding of customer behavior.
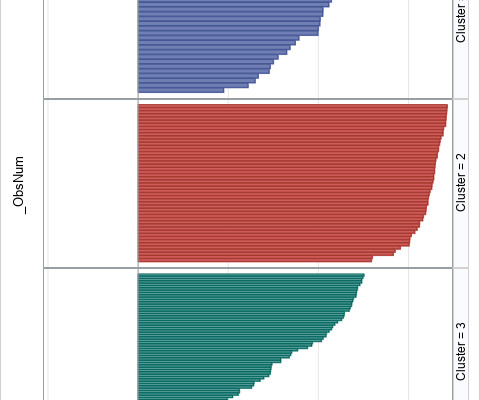
Assigning observations into clusters can be challenging. One challenge is deciding how many clusters are in the data. Another is identifying which observations are potentially misclassified because they are on the boundary between two different clusters. The post What is the silhouette statistic in clusteranalysis?
Data science tools are integral for navigating the intricate landscape of dataanalysis, enabling professionals to transform raw information into valuable insights. As the demand for data-driven decision-making grows, understanding the diverse array of tools available in the field of data science is essential.
Summary: Clustering in data mining encounters several challenges that can hinder effective analysis. Key issues include determining the optimal number of clusters, managing high-dimensional data, and addressing sensitivity to noise and outliers. What is Clustering?
In this second part of the Unsupervised Learning series, lets take a closer look at these three algorithms not just from a technical view, but by understanding the story behind their formulas.Because at the heart of every clustering strategy, its the measurement of similarity that makes all the difference.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in DataAnalysis. It excels in data cleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists. Why Python?
Data binning is an essential technique in data preprocessing that plays a pivotal role in dataanalysis and machine learning. The method is particularly beneficial when dealing with vast amounts of data, as it helps to reduce noise and handle various data challenges. .’
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays. The package is particularly useful for performing mathematical operations on large datasets and is widely used in machine learning, dataanalysis, and scientific computing.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform big data analytics and gain valuable insights from their data.
For years, spreadsheet programs like Microsoft Excel, Google sheet, and more sophisticated programs like Microsoft Power BI have been the primary tools for dataanalysis. Clustering. ?lustering There are a number of ready-made BI solutions that allow you to group data. Let’s dig deeper. Predictive analytics.
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It natively supports only numerical data, so typically an encoding is applied first for converting the categorical data into a numerical form. this link ).
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (clusteranalysis - CA) and classification are two important tasks that occur in our daily lives. Thus, this type of task is very important for exploratory dataanalysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content