This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To address this challenge, businesses need to use advanced dataanalysis methods. These methods can help businesses to make sense of their data and to identify trends and patterns that would otherwise be invisible. In recent years, there has been a growing interest in the use of artificial intelligence (AI) for dataanalysis.
Methods such as field surveys and manual satellite dataanalysis are not only time-consuming, but also require significant resources and domain expertise. This often leads to delays in data collection and analysis, making it difficult to track and respond swiftly to environmental changes. format("/".join(tile_prefix),
This is why businesses are looking to leverage machine learning (ML). For years, spreadsheet programs like Microsoft Excel, Google sheet, and more sophisticated programs like Microsoft Power BI have been the primary tools for dataanalysis. In this article, we will share some best practices for improving your analytics with ML.
These are important for efficient data organization, security, and control. Rules are put in place by databases to ensure data integrity and minimize redundancy. Moreover, organized storage of data facilitates dataanalysis, enabling retrieval of useful insights and data patterns.
Unsupervised ML: The Basics. Unlike supervised ML, we do not manage the unsupervised model. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
It involves data collection, cleaning, analysis, and interpretation to uncover patterns, trends, and correlations that can drive decision-making. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
However, the sheer volume of data and the high costs of conducting these experiments present major barriers to their widespread use. Thanks to machine learning (ML) and artificial intelligence (AI), it is possible to predict cellular responses and extract meaningful insights without the need for exhaustive laboratory experiments.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It provides a large cluster of clusters on a single machine.
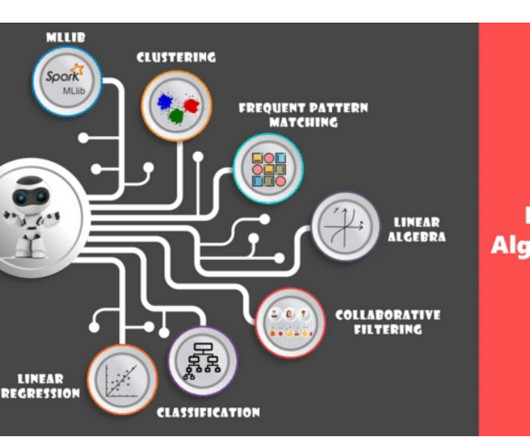
Pyspark MLlib | Classification using Pyspark ML In the previous sections, we discussed about RDD, Dataframes, and Pyspark concepts. In this article, we will discuss about Pyspark MLlib and Spark ML. using PySpark we can run applications parallelly on the distributed cluster… blog.devgenius.io
Let’s get started with the best machine learning (ML) developer tools: TensorFlow TensorFlow, developed by the Google Brain team, is one of the most utilized machine learning tools in the industry. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured dataanalysis.
Certainly, these predictions and classification help in uncovering valuable insights in data mining projects. ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. Both the hierarchical clustering and contentious clustering methods are seen as dendrogram.
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It natively supports only numerical data, so typically an encoding is applied first for converting the categorical data into a numerical form. this link ).
How this machine learning model has become a sustainable and reliable solution for edge devices in an industrial network An Introduction Clustering (clusteranalysis - CA) and classification are two important tasks that occur in our daily lives. Thus, this type of task is very important for exploratory dataanalysis.
This article will guide you through effective strategies to learn Python for Data Science, covering essential resources, libraries, and practical applications to kickstart your journey in this thriving field. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
One of the popular techniques for detecting anomalies or outliers in data is K-means clustering, a machine learning algorithm that can uncover patterns and groupings in large datasets. In this article, we will explore the application of K-means clustering to a credit card dataset to identify potential fraud cases.
Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 For instructions on how to provision an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with Amazon Elastic Compute Cloud (Amazon EC2) Linux managed nodes using eksctl, see Getting started with Amazon EKS – eksctl.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. AI and machine learning Building and deploying artificial intelligence (AI) and machine learning (ML) systems requires huge volumes of data and complex processes like high performance computing and big dataanalysis.
Business intelligence projects merge data from various sources for a comprehensive view ( Image credit ) Good business intelligence projects have a lot in common One of the cornerstones of a successful business intelligence (BI) implementation lies in the availability and utilization of cutting-edge BI tools such as Microsoft’s Fabric.
This mindset has followed me into my work in ML/AI. Because if companies use code to automate business rules, they use ML/AI to automate decisions. Given that, what would you say is the job of a data scientist (or ML engineer, or any other such title)? But first, let’s talk about the typical ML workflow.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Goodbye, Hadoop. And it was good.
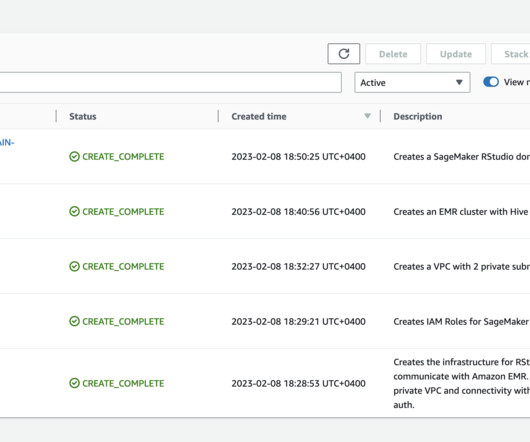
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. 1 Public subnet.
You can quickly launch the familiar RStudio IDE and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale. Data scientists and data engineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
Unlike supervised learning, where the algorithm is trained on labeled data, unsupervised learning allows algorithms to autonomously identify hidden structures and relationships within data. These algorithms can identify natural clusters or associations within the data, providing valuable insights for demand forecasting.
VizQL’s powerful combination of query and visual encoding led me to the following six innovation vectors in my analysis of Tableau’s history: Falling under the category of query , we’ll discuss connectivity , multiple tables , and performance. Gestalt properties including clusters are salient on scatters. Let’s take a look at each. .
By scrutinizing data packets that constitute network traffic, NTA aims to establish baselines of normal behavior, detect deviations, and take appropriate actions. This is where the power of machine learning (ML) comes into play. One of the primary applications of ML in network traffic analysis is anomaly detection.
Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Explanations around data, models , and blueprints are extensive throughout the platform so you’ll always understand your results. and train models with a single click of a button.
They classify, regress, or clusterdata based on learned patterns but do not create new data. In contrast, generative AI can handle unstructured data and produce new, original content, offering a more dynamic and creative approach to problem-solving. How is Generative AI Different from Traditional AI Models?
5 Industries Using Synthetic Data in Practice Here’s an overview of what synthetic data is and a few examples of how various industries have benefited from it. Going into developing machine learning models with a hands-on, data-centric AI approach has its benefits and requires a few extra steps to achieve. Here’s how.
Therefore, it mainly deals with unlabelled data. The ability of unsupervised learning to discover similarities and differences in data makes it ideal for conducting exploratory dataanalysis. There are different kinds of unsupervised learning algorithms, including clustering, anomaly detection, neural networks, etc.
Here is HuggingFace Link: [link] From the Mosaic ML paper. Here is the HuggingFace Link: [link] From the Mosaic ML paper. This is particularly advantageous in applications requiring long-term context retention, such as storytelling, documentation, or large-scale dataanalysis. This model was trained with 9.6M
Here are some ways AI enhances IoT devices: Advanced dataanalysis AI algorithms can process and analyze vast volumes of IoT-generated data. By leveraging techniques like machine learning and deep learning, IoT devices can identify trends, anomalies, and patterns within the data.
Knowing how spaCy works means little if you don’t know how to apply core NLP skills like transformers, classification, linguistics, question answering, sentiment analysis, topic modeling, machine translation, speech recognition, named entity recognition, and others.
Machine learning (ML) has proven that it is here with us for the long haul, everyone who had their doubts by calling it a phase should by now realize how wrong they are, ML has being used in various sector’s of society such as medicine, geospatial data, finance, statistics and robotics.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. You use pandas to load the metadata, then select products that have US English titles from the data frame. Now you’re going to create an index to store the catalog data and embeddings.
You can integrate a Data Wrangler data preparation flow into your machine learning (ML) workflows to simplify data preprocessing and feature engineering, taking data preparation to production faster without the need to author PySpark code, install Apache Spark, or spin up clusters.
Commercial LLMs remove the need for in-depth technical expertise in ML infrastructure. Use Case #1: Process Automation Process automation can be used to improve activities like framing images or analyzing data. In these cases, accuracy cannot be compromised, especially in dataanalysis. Accuracy is top priority here.
VizQL’s powerful combination of query and visual encoding led me to the following six innovation vectors in my analysis of Tableau’s history: Falling under the category of query , we’ll discuss connectivity , multiple tables , and performance. Gestalt properties including clusters are salient on scatters. Let’s take a look at each. .
When the preprocessing batch was complete, the training/test data needed for training was partitioned based on runtime and stored in Amazon S3. SageMaker pipeline for training SageMaker Pipelines helps you define the steps required for ML services, such as preprocessing, training, and deployment, using the SDK.
These communities will help you to be updated in the field, because there are some experienced data scientists posting the stuff, or you can talk with them so they will also guide you in your journey. DataAnalysis After learning math now, you are able to talk with your data.
The analysis of tons of data for your SaaS business can be extremely time-consuming, and it could even be impossible if done manually. Rather, AWS offers a variety of data movement, data storage, data lakes, big data analytics, log analytics, streaming analytics, and machine learning (ML) services to suit any need.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content