This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will discuss advanced topics in hives which are required for Data-Engineering. Whenever we design a Big-data solution and execute hive queries on clusters it is the responsibility of a developer to optimize the hive queries.
Introduction on Data Preprocessing In this article, we will learn how to perform filtering operations, so why do we need filter operations? The answer is being a dataengineers we have to deal with clusters of data and if we will start analyzing […].
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
Overview Learn about the Spark Architecture Learn about different execution modes Introduction Apache Spark is a unified computing engine and a set of. The post DataEngineering for Beginners – Get Acquainted with the Spark Architecture appeared first on Analytics Vidhya.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
This article was published as a part of the Data Science Blogathon Spark is a cluster computing platform that allows us to distribute data and perform calculations on multiples nodes of a cluster. The distribution of data makes large dataset operations easier to process.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using Natural Language Processing (NLP) or more specific from Named-Entity Recognition (NER). For DATANOMIQ this is a show-case of the coming Data as a Service ( DaaS ) Business.
AWS has many clusters of data centers in multiple countries across the globe. Introduction to AWS AWS, or Amazon Web Services, is one of the world’s most widely used cloud service providers. It is a cloud platform that provides a wide variety of services that can be used together to create highly scalable applications.
This article was published as a part of the Data Science Blogathon. Introduction Let’s say you want to create some clusters as fast as possible with less money. This is when Google Dataproc became the ideal tool that disables clusters when not in use and saves you money and time. […]. What services will you choose?
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Learn about supervised and unsupervised learning, classification, regression, clustering, and more. This detailed machine-learning roadmap can get you started with this step. Step 5. Work on projects Apply your knowledge by working on real-world data science projects.
Image by author #2 Label: Enabling the use of previously unusable data Organizations often have large amounts of data that are unused due to low quality or lack of labeling. Natural Language Processing (NLP) is an example of where traditional methods can struggle with complex text data.
It provides a large cluster of clusters on a single machine. Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like data analysis, fraud detection, and machine learning. It is also useful for training models on smaller datasets.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Orchestrate with Tecton-managed EMR clusters – After features are deployed, Tecton automatically creates the scheduling, provisioning, and orchestration needed for pipelines that can run on Amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
For the first time ever, the DataEngineering Summit will be in person! Co-located with the leading Data Science and AI Training Conference, ODSC East, this summit will gather the leading minds in DataEngineering in Boston on April 23rd and 24th. We’re currently hard at work on the lineup. Sign me up!
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem.
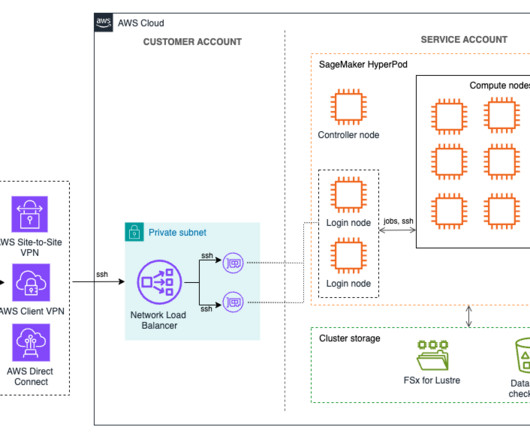
Multiple users such as ML researchers, software engineers, data scientists, and cluster administrators can work concurrently on the same cluster, each managing their own jobs and files without interfering with others. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
This explains the current surge in demand for dataengineers, especially in data-driven companies. That said, if you are determined to be a dataengineer , getting to know about big data and careers in big data comes in handy. Similarly, various tools used in dataengineering revolve around Scala.
This created a challenge for data scientists to become productive. Responsibility for maintenance and troubleshooting: Rockets DevOps/Technology team was responsible for all upgrades, scaling, and troubleshooting of the Hadoop cluster, which was installed on bare EC2 instances. Deployment initiation is controlled as part of CI/CD.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. These models may include regression, classification, clustering, and more.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
This blog lists down-trending data science, analytics, and engineering GitHub repositories that can help you with learning data science to build your own portfolio. What is GitHub? GitHub is a powerful platform for data scientists, data analysts, dataengineers, Python and R developers, and more.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
Evaluating Clustering in Machine Learning In this article, we’ll examine two renowned clustering evaluation methods: the Silhouette score and Density-Based Clustering Validation (DBCV). We’ll dive into their strengths, limitations, and ideal scenarios of use. We now have a podcast!
In conjunction with tools like RStudio on SageMaker, users are analyzing, transforming, and preparing large amounts of data as part of the data science and ML workflow. Data scientists and dataengineers use Apache Spark, Hive, and Presto running on Amazon EMR for large-scale data processing.
Photo by Aditya Chache on Unsplash DBSCAN in Density Based Algorithms : Density Based Spatial Clustering Of Applications with Noise. Earlier Topics: Since, We have seen centroid based algorithm for clustering like K-Means.Centroid based : K-Means, K-Means ++ , K-Medoids. & One among the many density based algorithms is “DBSCAN”.
Set up an Aurora MySQL database Complete the following steps to create an Aurora MySQL database to host the structured sales data: On the Amazon RDS console, choose Databases in the navigation pane. Under Settings , enter a name for your database cluster identifier. Delete the Aurora MySQL instance and Aurora cluster.
You can run Spark applications interactively from Amazon SageMaker Studio by connecting SageMaker Studio notebooks and AWS Glue Interactive Sessions to run Spark jobs with a serverless cluster. With interactive sessions, you can choose Apache Spark or Ray to easily process large datasets, without worrying about cluster management.
Prerequisites For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas. The following screenshots shows the setup of the data federation. Setup the Database access and Network access.
With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data.
Aggregating and preparing large amounts of data is a critical part of ML workflow. Data scientists and dataengineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. The following diagram represents the different components used in this solution. This is TLS enabled.
In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. Note: If you already have an RStudio domain and Amazon Redshift cluster you can skip this step. Amazon Redshift Serverless cluster.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon?
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. ML Governance: A Lean Approach Ryan Dawson | Principal DataEngineer | Thoughtworks Meissane Chami | Senior ML Engineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance.
Horizontal scaling increases the quantity of computational resources dedicated to a workload; the equivalent of adding more servers or clusters. Performance Before choosing a data warehousing solution, an organization must understand its latency and reliability requirements.
Unabhängiges und Nachhaltiges DataEngineering Die Arbeit hinter Process Mining kann man sich wie einen Eisberg vorstellen. Deep Learning auch anspruchsvollere Varianten-Cluster und Anomalien erkannt werden. Die sichtbare Spitze des Eisbergs sind die Reports und Analysen im Process Mining Tool.
PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities. The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time. Introduction Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content