This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several datalakes in Hadoop ecosystem.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. How to improve indexing.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. It can also be integrated into major data platforms like Snowflake.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Despite the benefits of this architecture, Rocket faced challenges that limited its effectiveness: Accessibility limitations: The datalake was stored in HDFS and only accessible from the Hadoop environment, hindering integration with other data sources. This also led to a backlog of data that needed to be ingested.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
Collecting, processing, and carrying out analysis on streaming data , in industries such as ad-tech involves intense dataengineering. The data generated daily is huge (100s of GB data) and requires a significant processing time to process the data for subsequent steps. What is Delta Lake?
Prerequisites For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas. The following screenshots shows the setup of the data federation. Setup the Database access and Network access.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions). They needed no additional infrastructure for data integration.
Algorithm Selection Amazon Forecast has six built-in algorithms ( ARIMA , ETS , NPTS , Prophet , DeepAR+ , CNN-QR ), which are clustered into two groups: statististical and deep/neural network. His team is responsible for designing, implementing, and maintaining end-to-end machine learning algorithms and data-driven solutions for Getir.
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products. so that organizations can focus on delivering value rather than be burdened by operational complexities.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. This provides end-to-end support for dataengineering and MLOps workflows.
Data Governance Account This account hosts data governance services for datalake, central feature store, and fine-grained data access. The SageMaker Project Portfolio has SageMaker projects that data scientists and ML engineers can use to accelerate model training and deployment.
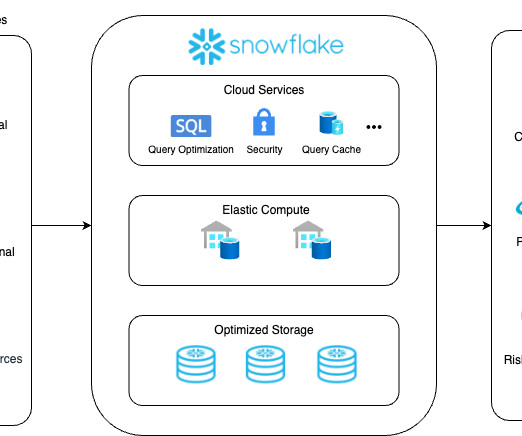
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Simplify and Win Experienced dataengineers value simplicity. What will You Attain with Snowflake?
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
However, building data-driven applications can be challenging. It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves dataengineers, data scientists, and business analysts using different systems and tools.
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for business intelligence and reporting purposes. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
phData has been working in dataengineering since the inception of the company back in 2015. We have seen customers transform their data analytics with Snowflake and transform their dataengineering and machine learning applications with Spark, Java, Scala, and Python.
Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data. You need dataengineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Explore the future of no-code ML with SageMaker Canvas today.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
When I was at Ford, we needed to hook things up to the car and telemetry it out and download all that data somewhere and make a datalake and hire a team of people to sort that data and make it usable; the blocker of doing any ML was changing cars and building datalakes and things like that.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content