This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
The big data boom was born, and Hadoop was its poster child. The promise of Hadoop was that organizations could securely upload and economically distribute massive batch files of any data across a cluster of computers. A datalake! Once again, garbage in-garbage out became a reality.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. When choosing a data structure, it may benefit you to see which has all the components of the CAP theorem and which best suits your needs. Drowning in Data? Professor Mark A.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
Each stage is crucial for deriving meaningful insights from data. Data gathering The first step is gathering relevant data from various sources. This could include data warehouses, datalakes, or even external datasets. This approach is useful for predicting outcomes based on historical data.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. It will enable you to quickly transform and load the data results into Amazon S3 datalakes or JDBC data stores.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. AWS Parallel Cluster for Machine Learning AWS Parallel Cluster is an open-source cluster management tool. Google Cloud.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
It supports various data types and offers advanced features like data sharing and multi-cluster warehouses. Amazon Redshift: Amazon Redshift is a cloud-based data warehousing service provided by Amazon Web Services (AWS). Airflow An open-source platform for building and scheduling data pipelines.
Set up a MongoDB cluster To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Delete the MongoDB Atlas cluster. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several datalakes in Hadoop ecosystem.
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. How to improve indexing.
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for business intelligence and reporting purposes. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
Prerequisites For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas. The following screenshots shows the setup of the data federation. Setup the Database access and Network access.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Well, let’s find out. Artificial intelligence (AI). Messages and notification.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and datalakes feel cumbersome and data pipelines just aren't agile enough.
Despite the benefits of this architecture, Rocket faced challenges that limited its effectiveness: Accessibility limitations: The datalake was stored in HDFS and only accessible from the Hadoop environment, hindering integration with other data sources. This also led to a backlog of data that needed to be ingested.
Organizations that want to build their own models or want granular control are choosing Amazon Web Services (AWS) because we are helping customers use the cloud more efficiently and leverage more powerful, price-performant AWS capabilities such as petabyte-scale networking capability, hyperscale clustering, and the right tools to help you build.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Architecture At its core, Redshift consists of clusters made up of compute nodes, coordinated by a leader node that manages communications, parses queries, and executes plans by distributing tasks to the compute nodes. Security features include data encryption and access control.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions). They needed no additional infrastructure for data integration.
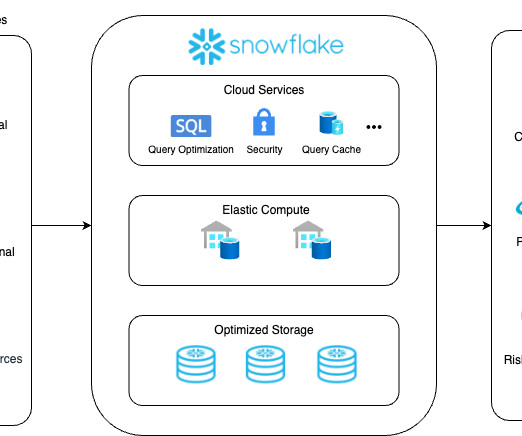
By offering native data engineering functionality inside of Snowflake virtual warehouses, we see a thriving data ecosystem being built around Snowflake. The release of Snowpark makes our customers’ lives simpler by unifying their datalake into a complete data platform.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity. Evaluation metrics include: Silhouette Coefficient - Measures the compactness and separation of clusters.
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. Explore the future of no-code ML with SageMaker Canvas today.
The gathering of data requires assessment and research from various sources. The data locations may come from the data warehouse or datalake with structured and unstructured data. Data Preparation: the stage prepares the data collected and gathered for preparation for data mining.
Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. This will ensure the data is in an ideal structure for further analysis.
Andre Franca | VP of Research and Development | causaLens Popular virtual sessions: AI and Bias: How to Detect It and How to Prevent It: Sandra Wachter, PhD | Professor, Technology and Regulation | Oxford Internet Institute, University of Oxford Probabilistic Machine Learning for Finance and Investing: Deepak Kanungo | Founder and CEO, Advisory Board (..)
Flexibility : NiFi supports a wide range of data sources and formats, allowing organizations to integrate diverse systems and applications seamlessly. Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow.
Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. Cluster Count If your warehouse has to serve many concurrent requests, you may need to increase the cluster count to meet demand.
Algorithm Selection Amazon Forecast has six built-in algorithms ( ARIMA , ETS , NPTS , Prophet , DeepAR+ , CNN-QR ), which are clustered into two groups: statististical and deep/neural network. Then the Step Functions “WaitInProgress” pipeline is triggered for each country, which enables parallel execution of a pipeline for each country.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
Automatically tracking data lineage across queries executed in any language. To ensure you can deliver on this world-changing vision of data, Alation helps you maximize the value of your datalake with integrations to the Unity catalog. An information scheme in the Lakehouse. … and much more!
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or datalake. DataLakes: These store raw, unprocessed data in its original format.
What are the similarities and differences between data centers, datalake houses, and datalakes? Data centers, datalake houses, and datalakes are all related to data storage and management, but they have some key differences. Not a cloud computer?
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products. so that organizations can focus on delivering value rather than be burdened by operational complexities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content