This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
The demand for higher data velocity, faster access and analysis of data as its created and modified without waiting for slow, time-consuming bulk movement, became critical to business agility. The big data boom was born, and Hadoop was its poster child. A datalake!
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access. Delete the MongoDB Atlas cluster.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
The size and the variety of data that enterprises have to deal with have become more complex and larger. Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. In traditional relational database engines, users can plan indexing to improve performance.
Note : Cloud Data warehouses like Snowflake and Big Query already have a default time travel feature. However, this feature becomes an absolute must-have if you are operating your analytics on top of your datalake or lakehouse. It can also be integrated into major data platforms like Snowflake. Contact phData Today!
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
A cloud data warehouse is designed to combine a concept that every organization knows, namely a data warehouse, and optimizes the components of it, for the cloud. What is a DataLake? A DataLake is a location to store raw data that is in any format that an organization may produce or collect.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. This article finally gets to the core question we started with: what can AWS do for your SaaS business?
When a query is constructed, it passes through a cost-based optimizer, then data is accessed through connectors, cached for performance and analyzed across a series of servers in a cluster. Because of its distributed nature, Presto scales for petabytes and exabytes of data.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
A data warehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Security features include data encryption and access control. Its PostgreSQL foundation ensures compatibility with most SQL clients.
eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
More on this topic later; but for now, keep in mind that the simplest method is to create a naming convention for database objects that allows you to identify the owner and associated budget. The extended period will allow you to perform Time Travel activities, such as undropping tables or comparing new data against historical values.
Types of Unstructured Data As unstructured data grows exponentially, organisations face the challenge of processing and extracting insights from these data sources. Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities. Businesses need to analyse data as it streams in to make timely decisions. This diversity requires flexible data processing and storage solutions.
Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity. Evaluation metrics include: Silhouette Coefficient - Measures the compactness and separation of clusters.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. Data can be structured (e.g., databases), semi-structured (e.g.,
There are 5 stages in unstructured data management: Data collection Data integration Data cleaning Data annotation and labeling Data preprocessing Data Collection The first stage in the unstructured data management workflow is data collection. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Flexibility : NiFi supports a wide range of data sources and formats, allowing organizations to integrate diverse systems and applications seamlessly. Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. To make data useful, we must be able to conduct large-scale compute easily. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch.
Streaming analytics tools enable organisations to analyse data as it flows in rather than waiting for batch processing. Variety Variety refers to the different types of data being generated. This section will highlight key tools such as Apache Hadoop, Spark, and various NoSQL databases that facilitate efficient Big Data management.
It acts as a catalogue, providing information about the structure and location of the data. · Hive Query Processor It translates the HiveQL queries into a series of MapReduce jobs. · Hive Execution Engine It executes the generated query plans on the Hadoop cluster. It manages the execution of tasks across different environments.
Cluster By: You can use the cluster_by config parameter to specify which column Snowflake should cluster the table. Ephemeral Ephemeral models are not a permanent part of the database. The ephemeral models can be reused in multiple downstream models, which would help you reduce clutter and organize your database.
Snowflake-managed Iceberg table’s performance is at par with Snowflake native tables while storing the data in public cloud storage. They are Ideal for situations where the data is already stored in datalakes and do not intend to load into Snowflake but need to use the features and performance of Snowflake.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products. so that organizations can focus on delivering value rather than be burdened by operational complexities.
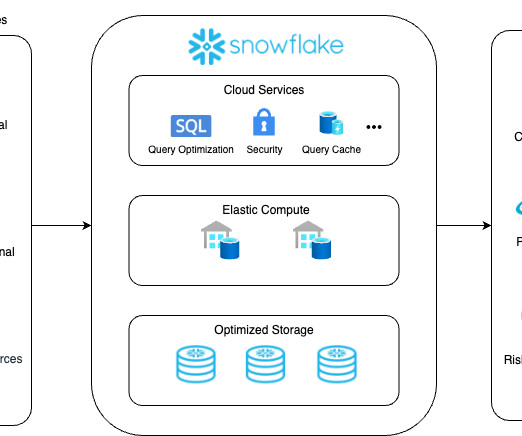
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Snowflake Database Pros Extensive Storage Opportunities Snowflake provides affordability, scalability, and a user-friendly interface.
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture.
What are the similarities and differences between data centers, datalake houses, and datalakes? Data centers, datalake houses, and datalakes are all related to data storage and management, but they have some key differences. Not a cloud computer?
Data is touched and manipulated by a myriad of solutions, including on-premises and cloud transformation tools, databases and datalake houses. It is rare for a site to have just one dedicated toolset. Resources from legacy systems, both defunct and active, along with new reporting tools, also play a role.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a datalake. Relational database connectors are available.
The job reads features, generates predictions, and writes them to a database. The client queries and reads the predictions from the database when needed. Inside the engine is a metrics data processor that: Reads the telemetry data, Calculates different operational metrics at regular intervals, And stores them in a metrics database.
A lot of the time, search engines are being shown like just pass some images through a pre-trained network, and then the features coming out of it will cluster this data sample, and that’s true, but if it clusters the way you think it should be, that is another story, right? Then they become incomparable most of the time.
And so data scientists might be leveraging one compute service and might be leveraging an extracted CSV for their experimentation. And then the production teams might be leveraging a totally different single source of truth or data warehouse or datalake and totally different compute infrastructure for deploying models into production.
And so data scientists might be leveraging one compute service and might be leveraging an extracted CSV for their experimentation. And then the production teams might be leveraging a totally different single source of truth or data warehouse or datalake and totally different compute infrastructure for deploying models into production.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content